Blog
All Blog Posts | Next Post | Previous Post

 Extend TMS WEB Core with JS Libraries with Andrew:
Extend TMS WEB Core with JS Libraries with Andrew:
Tabulator Part 2: Getting Data Into Tabulator
Wednesday, June 15, 2022

Last time out, we started our adventure into Tabulator, a JavaScript library that provides a grid-style control that you can use in your TMS WEB Core projects. This time out, we're going to focus on just one aspect - getting data into Tabulator. The material in this post may also be of general interest, no matter the grid control you're using, or even if you're just looking to get data into your TMS WEB Core application for any other use. We're going to dip our toe into SPARQL, used to query the data behind Wikipedia. We'll also show how to quickly set up an XData server as a proxy, both for SPARQL and other remote data sources. This should be fun!
Motivation.
Tabulator, and virtually every other JavaScript-based grid control, is expecting to get data in JSON format, where the various components involved along the way have differing levels of rigidity when it comes to the JSON format itself, unfortunately, as will see. Sometimes other formats are supported, like XML or CSV, but JSON is almost always the primary method. This isn't much of a surprise, of course, as JavaScript and JSON are very closely related to one another.
Many interesting remote sources of data can be accessed via a REST API, and will often also, if you ask politely, return data in a JSON format. All good. However, formulating requests acceptable to the remote server, and being able to actually get the bits of data out of the JSON that you get back, can sometimes be adventures all their own. And at the same time, there may be issues in terms of how much data you can request from a remote API or how fast it can serve up the data you are interested in. You might also be required to use an API key to make requests that you absolutely do not want to include in your TMS WEB Core application (or any JavaScript client application). And if you're accessing multiple remote data sources, you might be multiplying the potential headaches to come.
So in this post, we're going to contact multiple remote data sources. We're going to use a private API key. And we're going to address the performance aspects of the data we're using. Along the way, we'll also be looking to explore a broader array of data types (images, for example). And once we finally get hold of some data, we'll add it to a Tabulator table. We'll also see if we can add a few nice finishing touches along the way, to help balance some of the Tabulator content in other upcoming posts.
The example we're going to develop here is a simple one, at least to visualize. We want to use a date picker to select a birthday. With that birthday, we want to see a list of all of the actors (movies and TV shows) that share that birthday. And if we select an actor, we want to see all the movies and TV shows where they had a role. Sounds easy enough right?
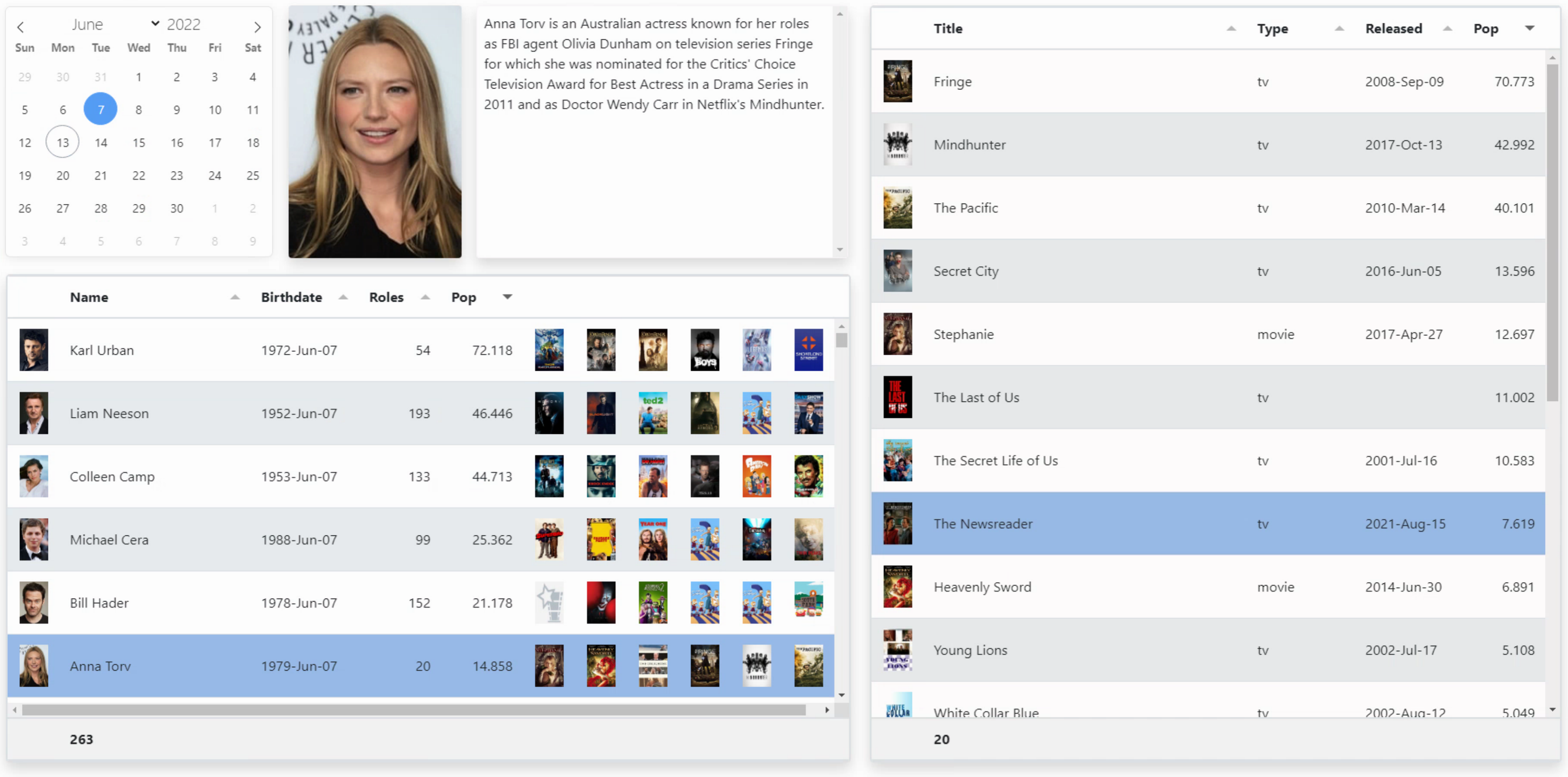
SPARQL.
Most of us are likely very familiar with SQL - used to query relational databases. I don't recall when I first used SQL, probably in university, but I do remember using it with DB2 running under OS/2. So yeah, it's been around forever, originally invented by IBM sometime in the mid-1970s. And it is great, no question. However, what do you use when you want to query a non-relational database? Well, if you're using the data that powers Wikipedia, it turns out there's a language called SPARQL that you can use, and they've even got an online query builder to help out. So what is SPARQL? Well, here's how Wikipedia describes it.
SPARQL (pronounced "sparkle" /ˈspɑːkəl/, a recursive acronym[2] for SPARQL Protocol and RDF Query Language) is an RDF query language—that is, a semantic query language for databases—able to retrieve and manipulate data stored in Resource Description Framework (RDF) format.
That wasn't all that helpful to me either, but the gist of it is that you can query data that is stored in WikiData, which covers quite a few subject areas. For our purposes, all we're interested in knowing at the outset is that (1) you can craft a query yourself for whatever data you're after, and (2) you can pass that query via a REST API endpoint and get a JSON dataset back. Perfect! As a bonus, you don't even need an API key or anything else really to get started. Maybe a little patience, though.
I'm no expert in SPARQL, having first heard of it when creating this post. But I do know a thing or two about SQL. This actually isn't all that helpful here, in retrospect, but the concepts are sort of the same - you're building a query with a bunch of conditions, and filtering the results based on some criteria. They have an interactive query builder (accessible from the same link above) that you can use to create queries initially. And then you can look at the generated query to see what it is doing. It is not too hard to muddle through it, but be sure to read through their online documentation, at least the first sample query, to get a bit more of a footing.
The query I'm after, for demonstration purposes here, is simple enough conceptually. I want to retrieve a list of all the TV and film actors listed on Wikipedia who have a birthday on a particular day of the year. And I'd also like to know what reference number to use when looking up information for them on The Movie Database (aka TMDb). TMDb is very similar to IMDb in many respects. I went with TMDb here as it seems their API is a little closer to what I need and their rules around access are a little more generous. In terms of the Wikipedia data, having a TMDb reference number (or an IMDb reference number, both are there) also helps serve as a filter so I don't get all the stage actors from the 1800s, for example.
And while it looks plenty unfriendly, the SPARQL query is reasonably easy to follow. All those question marks make it look like it is riddled with errors (No ?'s in SQL that I can recall!). I'd also like to state up-front that I have no idea how efficient this is. Other samples I've tinkered with while building this query weren't tremendously speedy either, so maybe this is just the level of performance it operates at. And if you were wondering, yes, SPARQL is another language supported by CodeMirror v5.
SELECT DISTINCT ?itemLabel ?DOB ?TMDbID WHERE {
?item p:P106 ?statement_0; # Occupation
p:P569 ?statement_1; # Birthdate
p:P4985 ?statement_2. # TMDb Entry
?statement_0 (ps:P106) wd:Q33999. # Occupation = Actor
?statement_1 psv:P569 ?statementValue_1. # Birthdate
?statement_2 ps:P4985 ?TMDbID. # TMDb Reference ID
?statementValue_1 wikibase:timeValue ?DOB. # Birthdate as a Date
FILTER (month(?DOB) = 5 ) # Filter by month
FILTER (day(?DOB) = 25 ) # Filter by day
# Need this to get the actor's actual name instead of just a Wikipedia link
SERVICE wikibase:label { bd:serviceParam wikibase:language "en". }
}The comments (#) should give a bit of an idea of what is going on here. There must be more performant ways to get at the same data, but we'll tackle that problem in a different way. Running this query in the online tool takes a bit of time, ranging from 10s to 40s. Somewhat inconsistent. Running it twice shows that it is cached, albeit briefly, returning in something like 15ms. Not sure whether I can even wrap my head around the infrastructure they must have in place for this to work for literally anyone who drops by, but it does indeed work.
The next step is then to figure out how to pass this query to WikiData and get the results back, within the confines of a TMS WEB Core application. To help with that, there are a few little nuggets of information that are important to have on hand.
- The REST API endpoint is https://query.wikidata.org/sparql.
- It is expecting a query via its ?query= parameter.
- The query is passed via a URL, so it needs to be encoded.
- We need to tell it to give us JSON back (it defaults to XML).
The service says it supports both GET and POST and that you should use POST when you have larger queries or when the query doesn't need to be cached. I had no luck using POST, as I ran into issues with CORS that didn't seem solvable. Switching to GET made everything work wonderfully. So fingers crossed that you don't need a query that can't be squeezed into a URL. What is the limit? Hard to say, but 2,000 characters might be a good number to keep in mind. Potentially much longer, though. For our query above, it converts to around 300 characters after getting rid of the comments and whitespace, so certainly plenty of room to grow.
One of the very few annoying aspects of the Delphi IDE is that it isn't really all that easy to store multi-line strings in code. You can do it, with quoted strings and line continuation characters and the rest of it. But it isn't all that fun. There are some IDE add-ons that can help, but all they do is add the quotes and line continuation characters, which is kind of not the point, although helpful and way better than nothing, certainly.
For our demo here, I've just added a hidden TWebMemo named sparqlACTORS to the form and added the above query. Be careful to set WordWrap to false. It isn't hidden from the web page entirely, but there's nothing particularly sensitive or interesting here, so we're not going to worry about it at the moment. This makes it far easier to edit the query, and also convenient for storing the original version if we want to mimic passing parameters to the query.
The parameters in this case will be a month and a day. We'll replace 5 and 25 in the above with :MONTH and :DAY to help this along. And just for fun, we'll use FlatPickr to create a calendar. Selecting a date will then trigger the SPARQL request and the results will get populated in a Tabulator table.
The main bits of code that we need are as follows. In WebFormCreate, we'll create the FlatPickr instance and the Tabulator instance and connect them to their respective TWebHTMLDivs that were dropped on the form. Nothing new going on here really, but you can refer to the previous post about FlatPickr and Tabulator for the details if you're not familiar with them. When a date is selected in the FlatPickr component, it calls GetBirthdays with the month and day selected. GetBirthdays then composes the query, submits it to WikiData, filters the results, and passes them to Tabulator.
unit Unit2;
interface
uses
System.SysUtils, System.Classes, JS, Web, WEBLib.Graphics, WEBLib.Controls,
WEBLib.Forms, WEBLib.Dialogs, Vcl.Controls, WEBLib.WebCtrls,
Vcl.StdCtrls, WEBLib.StdCtrls, WEBLib.REST;
type
TForm2 = class(TWebForm)
divTabulator: TWebHTMLDiv;
sparqlACTORS: TWebMemo;
divFlatPickr: TWebHTMLDiv;
procedure WebFormCreate(Sender: TObject);
[async] procedure GetBirthdays(aMonth: Integer; aDay: Integer);
private
{ Private declarations }
public
{ Public declarations }
end;
var
Form2: TForm2;
implementation
{$R *.dfm}
procedure TForm2.WebFormCreate(Sender: TObject);
begin
asm
var GetBirthdays = this.GetBirthdays;
flatpickr("#divFlatPickr", {
inline: true,
appendTo: divFlatPickr,
onChange: function(selectedDates, dateStr, instance) {
GetBirthdays(parseInt(dateStr.substr(5,2)), parseInt(dateStr.substr(8,2)));
}
});
var tabulator = new Tabulator("#divTabulator", {
layout: "fitData",
selectable: 1,
columns:[
{ title: "Name", field: "itemLabel.value", bottomCalc: "count" },
{ title: "Birthdate", field: "DOB.value", formatter: "datetime", formatterParams: {inputFormat: "iso", outputFormat:"yyyy-MMM-dd", timezone:"UTC"} },
{ title: "TMDb", field: "TMDbID.value" }
]
});
end;
end;
procedure TForm2.GetBirthdays(aMonth: Integer; aDay: Integer);
var
sparql: TWebHTTPRequest; // The request being sent to WikiDATA
qry: WideString; // The query portion of the GET URL (needs to be encoded)
req: TJSXMLHttpRequest; // The response coming back
data :WideString; // The response coming back, as text
good: Boolean; // Indicates whether we've got data
begin
// Get SPARQL query from TWebMemo (easier to edit there)
// First we replace the tokens with whatever date we've selected
// and then encode it so that it can be passed as part of the URL
qry := Form2.sparqlACTORS.Lines.Text;
qry := StringReplace(StringReplace(qry, ':MONTH', IntToStr(aMonth), [rfReplaceAll]), ':DAY', IntToStr(aDay), [rfReplaceAll]);
asm qry = encodeURIComponent(qry); end;
// Create the HTTP Request - defaults to httpGET
// Note: httpPOST isn't going to work with this endpoint
// NOTE: We want the result to come back as JSON, not XML
sparql := TWebHTTPRequest.Create(nil);
sparql.URL := 'https://query.wikidata.org/sparql?query='+qry;
sparql.Headers.AddPair('Accept','application/sparql-results+json');
good := false;
try
req := await(TJSXMLHttpRequest, sparql.Perform());
data := req.responseText;
good := True;
except
showmessage('nope');
end;
// If we're successful, load data into the table
if good then
begin
asm
var table = Tabulator.findTable("#divTabulator")[0];
var ds = JSON.parse(data);
table.replaceData(ds.results.bindings);
end;
end;
end;
end.There are a couple of sneaky things happening here, worth exploring a little further.
- Since it is the FlatPickr event handler that is triggering the call to GetBirthdays, we've lost our normal application context. This often happens when JavaScript events are called, as the caller is no longer the TMS WEB Core application but rather something else. The only problem this creates for us here is that we have to explicitly reference Form2 to be able to access the TWebMemo component.
- We're not using any form variables here, as we've done previously to keep track of our JavaScript component instances, so to make changes to the Tabulator table in a function or procedure after it has been created, a Tabulator lookup function is used.
- There are a couple of ways to request the data via JSON and we're using one here - setting a header value. We'll use the other one later, adding a query parameter.
- To get the query encoded as a URL, we just take a quick trip into JS and use their encodeURIComponent function.
- FlatPickr is set up with its default theme, and Tabulator is set up with a Bootstrap 5 theme.
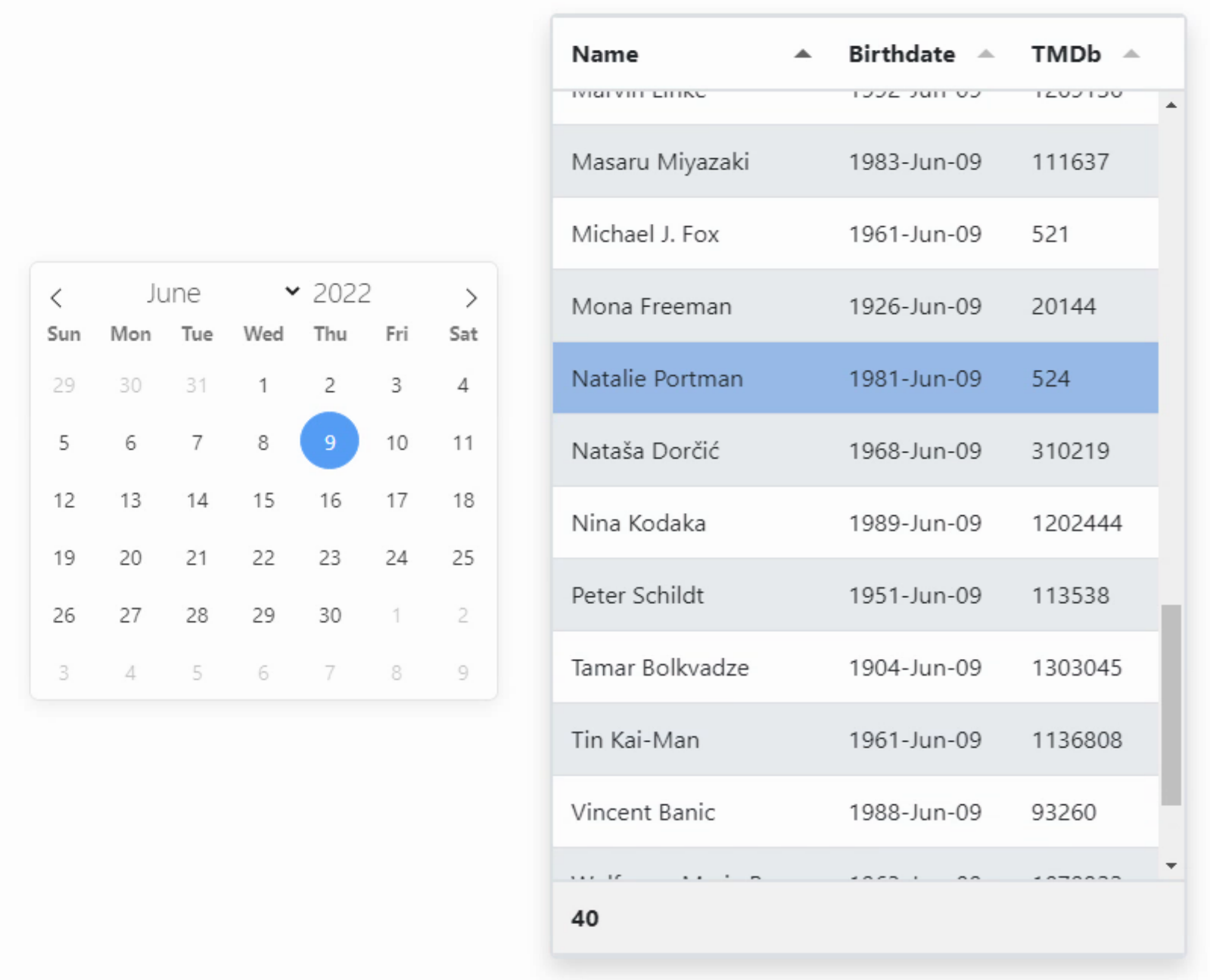
As far as the data itself is concerned, it is returned as JSON. We can specify what fields are returned in the SPARQL query, but we don't have much control beyond that. In general, getting JSON from a third party often involves having to process it to get the data into a format that we'd like. Sometimes this is trivial, and sometimes not so trivial.
In this case, there's a subset of the JSON data that contains the data we're after - the results.bindings key. Within that are the fields that we've requested, but they're structured in a way that each field has a set of child objects describing the datatype and the actual value. We're not doing anything fancy here, so we can just reference the 'value' child object as part of the field name that we pass to Tabulator (eg: DOB.value), and voila! Everything flows nicely.
All done, right? Oh, no. Not by a long shot. While this works, we're generally aiming a little higher. There are a few problems at this stage that we'll want to address, and in so doing, we will cover a bunch more ground related to our topic of "Getting Data Into Tabulator."
- Getting data from the query is painfully slow. Once it has been retrieved, requesting it again is really quick - WikiData is obviously caching requests. However, the cache doesn't last very long at all. So we'll want to have a cache of our own. But if we have millions of users (OK, dozens), maybe we can have a cache that benefits everyone, or even preload the cache so no one ever has to wait. While it might be a matter of being 'polite' to our data supplier to cache data in this case, there are plenty of cases where API access is logged and fees charged, so if you can minimize the load on those servers, it may dramatically reduce your costs (and theirs!). Some have rules about what you're allowed to cache and other things to keep in mind, however. And also the nature of the data you're after needs to be taken into account. Here, the data doesn't change frequently (weekly updates might be sufficient), but if this was some kind of account or transactional data, then it would be a different story.
- The data we've got is good, but how do we know which birthdays might be more interesting? There's not much to go on here. Wikipedia of course has a lot more data that we could use. Maybe how many acting credits they have, how much revenue has been generated in projects they've worked on. Or some other ranking. Getting that out of Wikipedia seems like it would not be very fun, but there are other sources of data. The Movie Database, for example, or IMDb, has this kind of data as well, and an available REST API. Curiously, though, no birthday search. Which is how I ended up at SPARQL in the first place. We can link them to get what we're after by using the TMDb reference information from our SPARQL query.
- While the data coming back from our query is usable, it has a fair bit of extra stuff in it that we don't ultimately need. And having the query itself embedded in the app, and relying on the client to do all this work is also not all that desirable. We could have a simpler client app, and a more performant one, if we can get this data already formatted in the way we want.
You can probably guess where this is headed next!
XData to the Rescue.
One of the more interesting ways to get data into a TMS WEB Core application (and ultimately into our Tabulator table) is to create a REST server of our own. Then it can be a proxy or a cache server, an agent between our client application and Wikipedia, or whatever other data sources we use. We can then do all the heavy lifting there, and set up endpoints that make it super simple to develop the client side. The XData server can also cache a huge amount of data (relative to, say, the browser on someone's aging mobile phone) and generally address all of the points mentioned above.
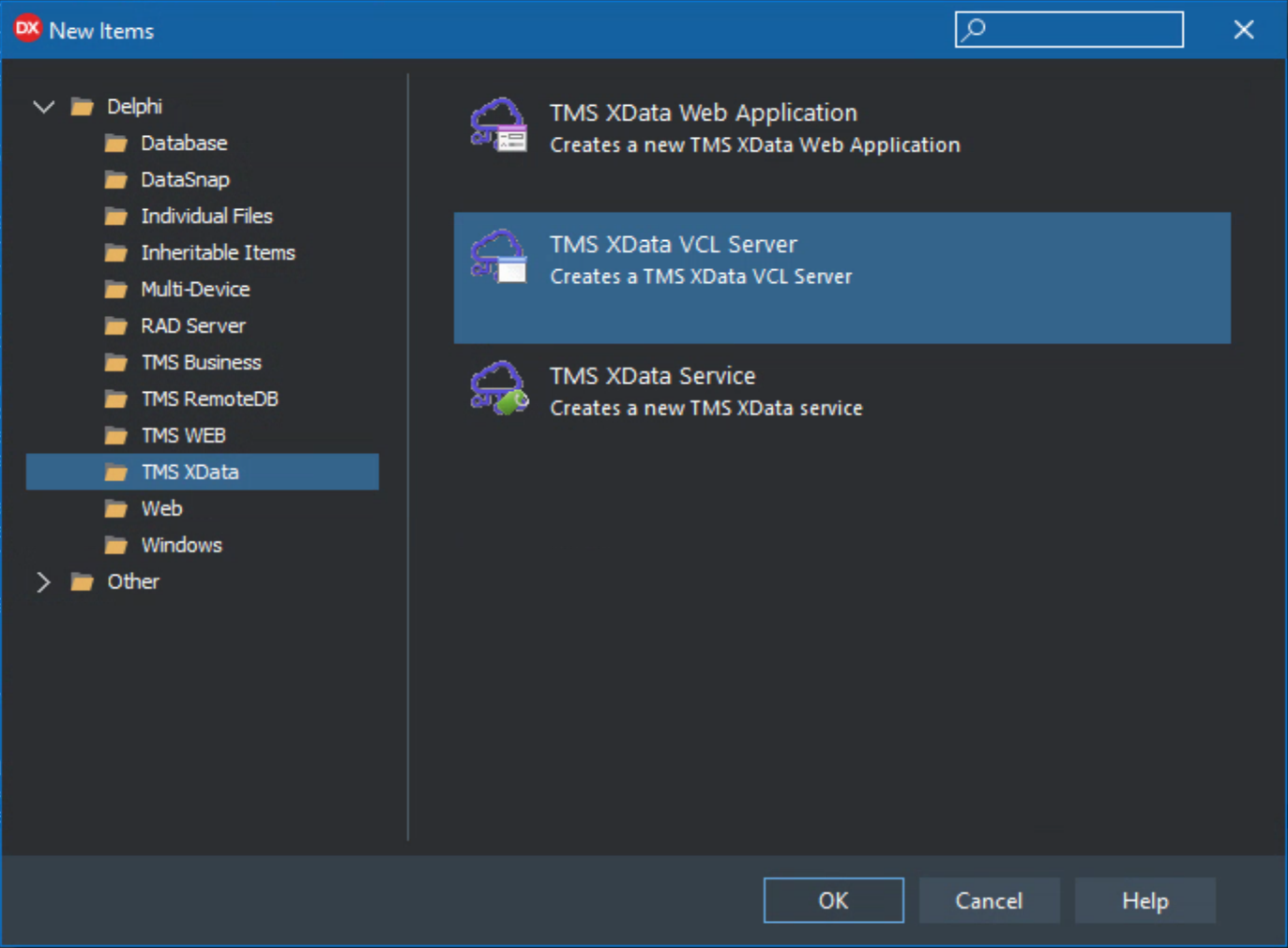
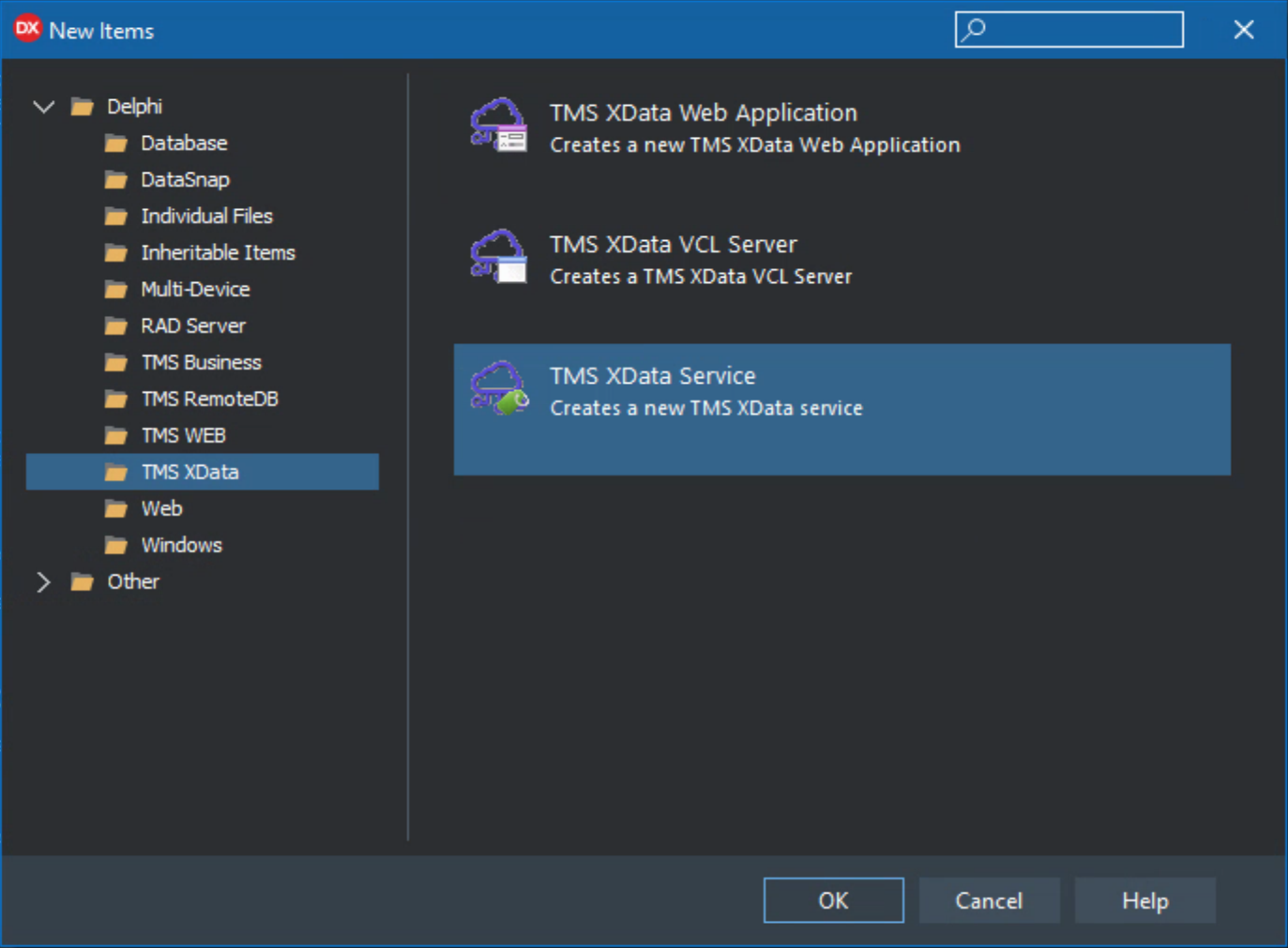
Alright, pretty easy so far. The next thing is to add a REST service endpoint. And there's a template for that too. Let's create a service called ActorInfo, just like the project folder name. We don't need the sample methods as we'll just be creating our own right away. Having separate interface and implementation units (the default) doesn't hurt.
Easy enough. There is now an interface unit, ActorInfoService.pas, and an implementation unit, ActorInfoImplementation.pas. Running the project prompts for the filenames, which are already set. The server doesn't do anything differently as we've not set up a service endpoint yet.
In ActorInfoService.pas, we can define the service endpoint for Birthdays to look like the following. We'll be expecting a 'secret' parameter, as well as the month and day, and we'll be returning a TStream that contains the JSON results. The 'secret' is just something to try and limit who can make use of the service. There are dozens of other things to consider for that topic, all very much beyond the scope of this blog post, so think of this as a placeholder for something more substantial. It is a stand-in for an API Key for your REST server.
unit ActorInfoService;
interface
uses
System.Classes,
XData.Service.Common;
type
[ServiceContract]
IActorInfoService = interface(IInvokable)
['{D0697F1E-EE4C-47D1-A29E-0B19B5D396FD}']
/// <summary>
/// Birthdays
/// </summary>
/// <remarks>
/// Returns a list of Actors with a birthday that falls on the supplied month and day.
/// </remarks>
/// <param name="Secret">
/// If I told you, it wouldn't be a secret.
/// </param>
/// <param name="BirthMonth">
/// Birth Month (1-12).
/// </param>
/// <param name="BirthDay">
/// Birth Day (1-31).
/// </param>
[HttpGet] function Birthdays(Secret: String; BirthMonth: Integer; BirthDay: Integer):TStream;
end;
implementation
initialization
RegisterServiceType(TypeInfo(IActorInfoService));
end.
In order to use TStream, the System. Classes unit was added. The comments before the endpoint definition can be used to generate a Swagger website as part of the project. Which works really great. I quite like it. To enable it, we'll need to do a few quick things. And we also need to add something to help with CORS while we're at it.
procedure TServerContainer.DataModuleCreate(Sender: TObject);
begin
TXDataModelBuilder.LoadXMLDoc(XDataServer.Model);
XDataServer.Model.Title := 'Actor API';
XDataServer.Model.Version := '1.0';
XDataServer.Model.Description :=
'### Overview'#13#10 +
'This is an API for accessing stuff.';
end;
Now, when the application is running, point your browser at http://localhost:2001/tms/xdata/swaggerui, and with a little luck, you should see something like the following. We can't use it directly yet as we've not written any of the implementation code.
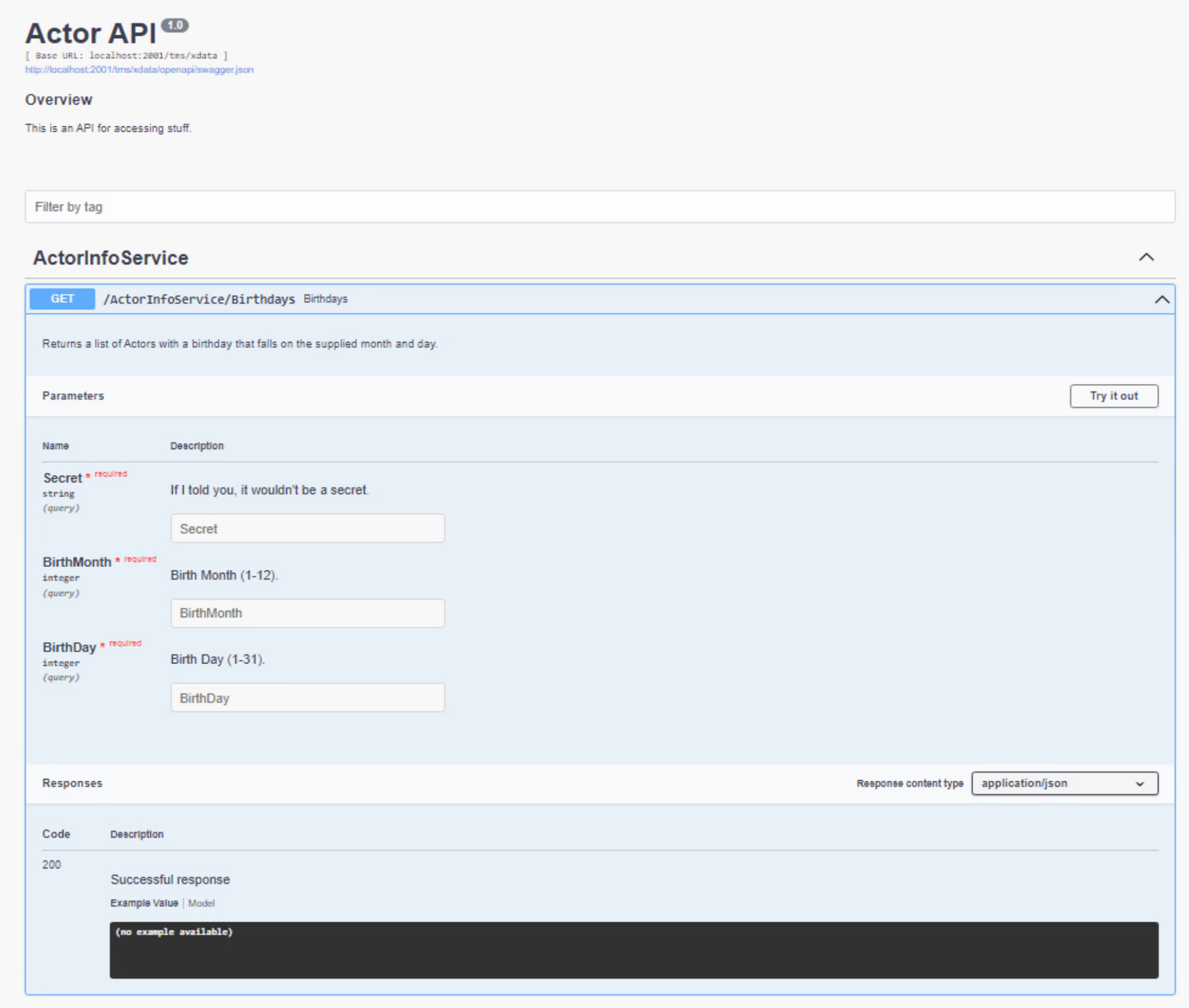
For the implementation, well, we already know what we want it to do. Essentially the same thing we were already doing in the client application. Let's start with that. This is a bit more tricky as it is a Delphi VCL app now, not a TMS WEB Core app, so no flitting about between Pascal and JavaScript, unfortunately, but we can still get the job done all the same. Kind of curious how this is all easier in TMS WEB Core, actually, where things like SSL are simply not a concern.
We can also do a little error checking and validation to make sure we're not wasting any time running invalid queries, or serving up data to people who are not authorized, even in this trivial example of security. XData can raise exceptions that are passed back to the client, so we'll add a couple here.
And all we're doing with the data is creating a JSON object, more as a test that it works, and then passing the JSON back through to the client. In a moment we'll do some intermediate processing. But for now, the XData service is doing what the client was doing previously, including referencing the query in a Memo component added to Unit2 to hold the SPARQL query. The result is the following.
unit ActorInfoServiceImplementation;
interface
uses
System.Classes,
System.SysUtils,
System.JSON,
XData.Server.Module,
XData.Service.Common,
XData.Sys.Exceptions,
IdHTTP, IdSSLOpenSSL, idURI,
ActorInfoService;
type
[ServiceImplementation]
TActorInfoService = class(TInterfacedObject, IActorInfoService)
function Birthdays(Secret: String; BirthMonth: Integer; BirthDay: Integer):TStream;
end;
implementation
uses Unit2;
{ TActorInfoService }
function TActorInfoService.Birthdays(Secret: String; BirthMonth, BirthDay: Integer):TStream;
var
sparql: TIdHTTP; // The request being sent to WikiDATA
SSLHandler: TIdSSLIOHandlerSocketOpenSSL ; // SSL stuff
qry: String; // The query (needs to be encoded)
req: UTF8String; // The response coming back
data :TJSONObject; // The response encoded as JSON
begin
// First, did they send the correct secret?
if (Secret <> 'LeelooDallasMultiPass') then raise EXDataHttpUnauthorized.Create('Access Not Authorized');
// Second, did they request a valid day? NOTE: 2020 was chosen as it is a leap year
try
EncodeDate(2020, BirthMonth, BirthDay);
except on E: Exception do
begin
raise EXDataHttpException.Create('Invalid Birthday');
end;
end;
// Alright, seems like we've got a valid request.
Result := TMemoryStream.Create;
TXDataOperationContext.Current.Response.Headers.SetValue('content-type', 'application/json');
// Get SPARQL query from TMemo (easier to edit there)
// First we replace the tokens with whatever date we've selected
// and then encode it so that it can be passed as part of the URL
// NOTE: We want the result to come back as JSON, not XML
qry := MainForm.sparqlACTORS.Lines.Text;
qry := StringReplace(StringReplace(qry, ':MONTH', IntToStr(BirthMonth), [rfReplaceAll]), ':DAY', IntToStr(BirthDay), [rfReplaceAll]);
qry := TidURI.URLEncode('https://query.wikidata.org/sparql?query='+qry+'&format=json');
// Bunch of stuff to support SSL.
// Need to install latest OpenSSL Win64 DLL's in debug folder
// Can get the latest version from: https://indy.fulgan.com/SSL/
SSLHandler := TIdSSLIOHandlerSocketOpenSSL.Create(nil);
SSLHandler.SSLOptions.Method := sslvTLSv1_2;
// Create the HTTP Request - defaults to httpGET
// Note: httpPOST isn't going to work with this endpoint
sparql := TidHTTP.Create(nil);
sparql.IOHandler := SSLHandler ; //set HTTP IOHandler for SSL Connection
try
req := sparql.Get(qry);
data := TJSONObject.ParseJSONValue(req) as TJSONObject;
req := data.tostring;
Result.WriteBuffer(Pointer(req)^, length(req));
except on E: Exception do
begin
raise EXDataHttpException.Create('Nope');
end;
end;
end;
initialization
RegisterServiceType(TActorInfoService);
end.We can now use the Swagger client to test the API by filling in the secret and selecting different months and days. It isn't any faster yet, but you should see a nicely formatted JSON result returned for each valid date entered, and appropriate exception messages if you don't enter the secret, or if you enter an invalid date.
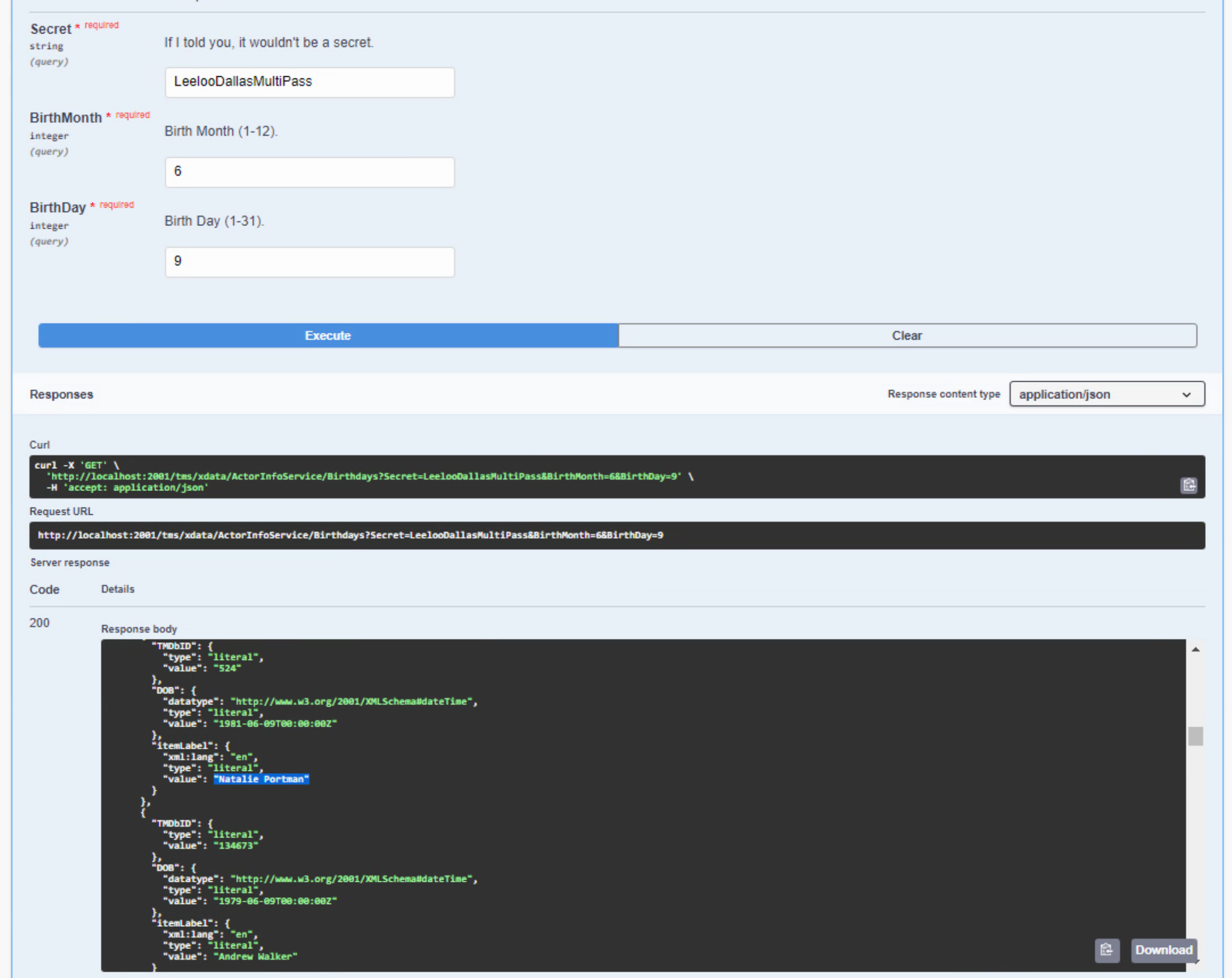
If we shift our attention back to the client application, we can replace GetBirthday with the following, initially. We'll change it next time to be better able to process the potential exceptions, but this gets us to where we were already.
Just for fun, we'll encode the secret in Base64 in the client app. Note that this is really not any more secure as you can see the decoded secret in the browser development tools by looking at the network traffic, with almost no effort at all. The old saying, "locked doors keep honest people honest" applies here. Realistically, access to any REST API should be handled with proper logins and JWTs and the rest of it.
procedure TForm2.GetBirthdays(aMonth: Integer; aDay: Integer);
var
birthdays: TWebHTTPRequest; // The request being sent to our XData service endpoint
req: TJSXMLHttpRequest; // The response coming back
data :WideString; // The response coming back, as text
good: Boolean; // Indicates whether we've got data
begin
birthdays := TWebHTTPRequest.Create(nil);
birthdays.URL := 'http://localhost:2001/tms/xdata/ActorInfoService/Birthdays';
birthdays.URL := birthdays.URL+'?Secret='+window.atob('TGVlbG9vRGFsbGFzTXVsdGlQYXNz');
birthdays.URL := birthdays.URL+'&BirthMonth='+IntToStr(amonth);
birthdays.URL := birthdays.URL+'&BirthDay='+IntToStr(aDay);
good := false;
try
req := await(TJSXMLHttpRequest, birthdays.Perform());
data := req.responseText;
good := True;
except
showmessage('nope');
end;
// If we're successful, load data into the table
if good then
begin
asm
var table = Tabulator.findTable("#divTabulator")[0];
var ds = JSON.parse(data);
table.replaceData(ds.results.bindings);
end;
end;
end;Caching Requests.
We didn't go through all that to end up with the same user experience, so let's have a look at caching. For this particular application, the data doesn't change often. Could probably cache it for a year and it wouldn't really matter. Daily weather data is also a good candidate for caching, with retention set at daily, naturally. But many sources of data can benefit from caching, even for a short period. Whether that applies to your data is up to you of course, and as we've touched on already, transactional data tends to be less of a candidate.
In this application, a cache is not complicated. There are 366 possible birthdays (don't forget about February 29th!), therefore we've got 366 sets of possible responses that could be cached. We'll just have an array of responses indexed to the day of the year.
There's a lot that could be said here about multi-threading and the nature of service endpoint requests, which each run in their own threads. We're assuming that two requests aren't updating the cache at the same time and that the cache can be accessed by multiple threads. The implementation then doesn't change too much. But we'll also take this as an opportunity to filter what we're getting from SPARQL so that our cache is a bit smaller, and easier to digest on the client side - just a JSON array of our three fields.
function TActorInfoService.Birthdays(Secret: String; BirthMonth, BirthDay: Integer):TStream;
var
sparql: TIdHTTP; // The request being sent to WikiDATA
SSLHandler: TIdSSLIOHandlerSocketOpenSSL ; // SSL stuff
qry: String; // The query (needs to be encoded)
req: UTF8String; // The response coming back
data: TJSONArray; // The response paired down to the relevant JSON array
cacheindex: Integer; // Julian day of birthday selected
cacheentry: UTF8String; // New value of cache
i: integer;
begin
// First, did they send the correct secret?
if (Secret <> 'LeelooDallasMultiPass') then raise EXDataHttpUnauthorized.Create('Access Not Authorized');
// Second, did they request a valid day?
try
cacheindex := DayOfTheYear(EncodeDate(2000, BirthMonth, BirthDay));
except on E: Exception do
begin
raise EXDataHttpException.Create('Invalid Birthday');
end;
end;
// Alright, seems like we've got a valid request.
Result := TMemoryStream.Create;
TXDataOperationContext.Current.Response.Headers.SetValue('content-type', 'application/json');
// Is a cached result available?
if Mainform.Birthdays[cacheindex] <> '[]' then
begin
cacheentry := Mainform.Birthdays[cacheindex];
Result.WriteBuffer(Pointer(cacheentry)^, length(cacheentry));
end
else
begin
// Get SPARQL query from TMemo (easier to edit there)
// First we replace the tokens with whatever date we've selected
// and then encode it so that it can be passed as part of the URL
// NOTE: We want the result to come back as JSON, not XML
qry := MainForm.sparqlACTORS.Lines.Text;
qry := StringReplace(StringReplace(qry, ':MONTH', IntToStr(BirthMonth), [rfReplaceAll]), ':DAY', IntToStr(BirthDay), [rfReplaceAll]);
qry := TidURI.URLEncode('https://query.wikidata.org/sparql?query='+qry+'&format=json');
// Bunch of stuff to support SSL.
// Need to install latest OpenSSL Win64 DLL's in debug folder
// Can get the latest version from: https://indy.fulgan.com/SSL/
SSLHandler := TIdSSLIOHandlerSocketOpenSSL.Create(nil);
SSLHandler.SSLOptions.Method := sslvTLSv1_2;
// Create the HTTP Request - defaults to httpGET
// Note: httpPOST isn't going to work with this endpoint
sparql := TidHTTP.Create(nil);
sparql.IOHandler := SSLHandler ; //set HTTP IOHandler for SSL Connection
try
req := sparql.Get(qry);
data := ((TJSONObject.ParseJSONValue(req) as TJSONObject).getValue('results') as TJSONObject).getValue('bindings') as TJSONArray;
cacheentry := '[';
for i := 0 to data.Count - 1 do
begin
cacheentry := cacheentry+'{';
cacheentry := cacheentry+'"ID":'+IntToStr(i+1)+',';
cacheentry := cacheentry+'"Name":"'+(((data.Items[i] as TJSONObject).getValue('itemLabel') as TJSONObject).getValue('value') as TJSONString).value+'",';
cacheentry := cacheentry+'"DOB":"' +(((data.Items[i] as TJSONObject).getValue('DOB') as TJSONObject).getValue('value') as TJSONString).value+'",';
cacheentry := cacheentry+'"TMDb":"'+(((data.Items[i] as TJSONObject).getValue('TMDbID') as TJSONObject).getValue('value') as TJSONString).value+'"';
cacheentry := cacheentry+'}';
if i < data.count - 1
then cacheentry := cacheentry+',';
end;
cacheentry := cacheentry+']';
MainForm.Birthdays[cacheindex] := cacheentry;
except on E: Exception do
begin
raise EXDataHttpException.Create('Nope');
end;
end;
Result.WriteBuffer(Pointer(cacheentry)^, length(cacheentry));
end;
end;And in MainForm (Unit2) we just add a Birthday array to the Form and initialize it when the form is created.
unit Unit2;
interface
uses
Winapi.Windows, Winapi.Messages, System.SysUtils, System.Variants,
System.Classes, Vcl.Graphics, Vcl.Controls, Vcl.Forms, Vcl.Dialogs,
Vcl.StdCtrls, Unit1;
type
TMainForm = class(TForm)
mmInfo: TMemo;
btStart: TButton;
btStop: TButton;
sparqlACTORS: TMemo;
procedure btStartClick(ASender: TObject);
procedure btStopClick(ASender: TObject);
procedure FormCreate(ASender: TObject);
public
Birthdays: Array[1..366] of UTF8String;
strict private
procedure UpdateGUI;
end;
var
MainForm: TMainForm;
implementation
{$R *.dfm}
resourcestring
SServerStopped = 'Server stopped';
SServerStartedAt = 'Server started at ';
{ TMainForm }
procedure TMainForm.btStartClick(ASender: TObject);
begin
ServerContainer.SparkleHttpSysDispatcher.Start;
UpdateGUI;
end;
procedure TMainForm.btStopClick(ASender: TObject);
begin
ServerContainer.SparkleHttpSysDispatcher.Stop;
UpdateGUI;
end;
procedure TMainForm.FormCreate(ASender: TObject);
var
i: Integer;
begin
for i := 1 to 366 do
begin
Birthdays[i] := '[]';
end;
UpdateGUI;
end;
procedure TMainForm.UpdateGUI;
const
cHttp = 'http://+';
cHttpLocalhost = 'http://localhost';
begin
btStart.Enabled := not ServerContainer.SparkleHttpSysDispatcher.Active;
btStop.Enabled := not btStart.Enabled;
if ServerContainer.SparkleHttpSysDispatcher.Active then
mmInfo.Lines.Add(SServerStartedAt + StringReplace(
ServerContainer.XDataServer.BaseUrl,
cHttp, cHttpLocalhost, [rfIgnoreCase]))
else
mmInfo.Lines.Add(SServerStopped);
end;
end.The result is a simpler set of JSON returned by XData. And whenever a date has been selected that was selected previously (found in the cache), the response is generated immediately, rather than in 20s or so.

On the client, no substantial changes are required, as caching is strictly a server-side issue. Just an update to the field names to reflect minor changes, and no need to do anything to the JSON as it is already processed. But if we ever restart the XData server, the cache is reset. So let's add a feature to load and save the cache.
BirthdayCache is a variable that holds the cache filename, and these functions are wired up to buttons in the main UI. Nothing too fancy, and not a lot of error checking going on here, but the cache is written out as a JSON array, containing 366 separate JSON arrays that are the individual responses for each birthday. All in, a fully populated cache would likely be on the order of 10 MB, so nothing to be too concerned about. Nor is it likely to grow substantially at any point with just this data.
Invalidating the cache (so it eventually gets refreshed) could be done by just having a timer that periodically sets each Birthdays' array value to [] in order, once every four minutes, which would reset the entire cache about once per day and still be below the threshold set by WikiData. Anyone accessing a reset value would result in that cache being refreshed. The timer could do this as well so that there are no cache misses. How this is configured depends on whether you're trying to maximize the freshness of the cache, the wait time for the end user, the traffic to WikiData, and so on.
For this application, we probably don't care about the freshness of the cache, we do care about WikiData traffic, but we mostly care about wait times. So no cache invalidation is done. Maybe once a month, the cache file could be deleted, for example, and then rebuilt as client requests come in. Nothing but options here, and none that are particularly difficult to implement.
procedure TMainForm.btSaveBirthdaysClick(Sender: TObject);
var
data :TStringList;
i: integer;
begin
// Save birthdays to a file as JSON
data := TStringList.Create;
data.Add('[');
for i := 1 to 366 do
begin
if i < 366
then data.Add(Birthdays[i]+',')
else data.Add(Birthdays[i]);
end;
data.Add(']');
data.SavetoFile(BirthdayCache);
end;
procedure TMainForm.btLoadBirthdaysClick(Sender: TObject);
var
data: TStringList;
jsondata: TJSONArray;
i:Integer;
begin
// Load birthdays from a file as JSON
data := TSTringList.Create;
try
data.LoadFromFile(BirthdayCache);
except on E: Exception do
begin
mmInfo.Lines.Add('WARNING: Birthday Cache file not loaded: '+BirthdayCache);
end;
end;
if data.text <> '' then
begin
jsondata := TJSONObject.ParseJSONValue(data.text) as TJSONArray;
for i := 0 to 365 do
begin
Birthdays[i+1] := (jsondata.items[i] as TJSONArray).ToString;
end;
end;
end;More Data.
With that all working well, the next step is to get more data into our client application. Things like photos of the actor, the movies or TV shows they've been in, and other elements that can help us sort the list in various ways.
While we could possibly use the same data source to get this information, we're instead going to use The Movie Database (TMDb) to retrieve this information. It gives us a simpler API to use, as well as data already structured more closely to what we're interested in. Here we also find an example of a REST API that requires the use of an API Key. Which, while technically not very complicated, brings up the security topic again - how to protect this kind of information from prying eyes. Using our own XData server mitigates this to a large degree, as then the client doesn't see it at all. And this is a common way to hide API keys - use them in your own server and proxy the requests.
Somewhere on TMDb.org's to-do list is to be able to query their database by actor birthday. But as we can't do that yet, we'll just use the birthdays we already have, and work from there. So what information do we want? A photo of the actor and something to indicate their popularity would be a great start. We'd also like to know all the roles they've had and perhaps a photo of the movie or TV Show and the name of their character. So, quite a lot, actually. But this is all readily available information. Too much information, in fact, so we'll have to pick and choose what we want.
We'll also set up a separate endpoint, BirthdaysExtended, to do this part of the job. It will rely on the Birthdays that have been cached (or will call the original endpoint to populate the cache, if needed) and then use the list of actors on the requested date to pass requests to TMDb. Individual requests to TMDb are considerably quicker than to WikiData, but unfortunately, there are a lot of people with birthdays on any given day, so ultimately the calls to TMDb add up to an even longer request. But we can cache that data the same way as we were doing before. The only caveat here is that there is considerably more data we'll be caching, on the order of 1-2 MB per date, so maybe 500 MB for everything. That's quite a lot but not so much that we're going to worry about it at the moment.
When it comes to what to cache, how much to cache, and so on, we're really just trying to wrestle with how many requests we want to make between the client application and the XData server, how much data can be handled in each request, and how much data can XData cache in an efficient manner, versus just sending requests to TMDb.
For now, we're set up for one XData request per birthday selected, with up to 1 MB returned in a request. Which is quite a lot, admittedly, and that doesn't even include the images that need to be downloaded by the client (we just pass the image paths). This could (and probably should) be optimized further, and the first approach would be to limit the number of people returned for each date. But we don't yet know who to cull from that list, so we'll leave it as is. Some additional criteria can likely be used to great effect here.
The next hiccup we have to address is that the data coming from TMDb is considerably more than we need. So we'll need to knead it a little bit to get what we want from it. We're looking for a bit of information about each actor (kind of like a header row) and then a bunch of information about each of their roles (kind of like detail rows).
What we're doing here is taking in the TMDb JSON and outputting our own JSON that has just what we want. We also have to jump through a few hoops as sometimes data sources aren't always so keen to play by the rules. There are a few areas where this has come up with TMDb, but not too hard to manage.
- JSON, and its strings, are formatted in a specific way, just like URL (or URI) encoding. But sometimes data comes along that (presumably innocently) breaks some of these rules. One of them relates to the tab character. The JSON specification says tabs are allowed between JSON elements but not in JSON strings. We've anticipated shenanigans in JSON strings (this is publicly editable data, just like Wikipedia, after all) but alas the methods we used here didn't seem to catch all the tabs. So at the very end, we simply strip ALL the tabs from the entire JSON result set. Harder to find the problem than to fix it, in this case.
- TMDb returns different data for TV and Movie results. Movies have 'title' elements, for example, whereas TV Shows have 'name' elements. Similarly, Movies have "release_date' elements vs. TV Show 'first_air_date' elements. Little differences are kind of a pain when you want them combined. The code is more complicated as a result of this, but that's typical, at least from my experience, when dealing with external data sources. There's always some little thing to worry about.
- Sometimes JSON elements have a null value. Sometimes JSON elements are simply missing. The code to deal with these are different, and they appear in the data in different ways. For example, someone's birthday may not be listed in the TMDb database, so there will be a JSON element, but it will be null. In other cases, the element is simply not always included if it doesn't apply (an optional element). So there is more error checking being done to handle these cases than seems normal. We could just pass the data that exists and leave out the data that doesn't (might do that later) but I was more interested in having consistent data to deal with than I was in reducing the space taken up by empty or null elements.
- Images are another example of this, where sometimes there is a movie or an actor that has no image available, so we end up with a null value. We'll address that more with the client. But a note about images. We could also incorporate the images into the JSON and pass them in the same way. Something I had mulled over until I saw the size of the array after... Maybe not such a good idea. However, another reason not to is that by having the client load the images, the client browser can do the caching, particularly as many images are going to be repeated (popular movies for example). And the browser can also do the lazy loading that wouldn't happen if all the images were passed to the client at once via JSON.
- An element called 'Roles' shows a count of how many different Movies and TV Shows are linked to the actor. A separate element called Work contains a JSON array of all of them, along with enough information to populate a detail table. The code sort of looks like we're duplicating a few things and that's because, well, we are.
- As part of the "header" portion of the actor information, I wanted to show the most popular works for that actor. But it turns out that the 'popularity' figure is calculated differently for Movies and TV Shows. Sean Connery, for example, has a bunch of TV Shows listed as his most popular works, but clearly not the results we're after. So instead I created two lists, one for Movies and one for TV Shows, and then take the top three of each. So six of these end up in the header, and thus we can display six images alongside the list of actor names. Tedious, to be sure.
With all that out of the way, I present to you (in the voice of Sean Connery of course!) the BirthdaysExtended endpoint code.
function TActorInfoService.BirthdaysExtended(Secret: String; BirthMonth, BirthDay: Integer): TStream;
var
TMDb: TIdHTTP; // The request being sent to TMDb
SSLHandler: TIdSSLIOHandlerSocketOpenSSL ; // SSL stuff
qry: String; // What we're asking for
data: TJSONObject; // Response converted to JSON
role: TJSONObject; // A particular role found in the data
actors: TJSONArray;
req: UTF8String;
RolePopularityTV: TSTringList;
RolePopularityMovie: TSTringList;
response: UTF8String;
cacheindex: Integer;
cacheentry: UTF8String;
i: integer; // used for iterating list of roles (movies, tv shows)
j: integer; // used for iterating list of birthdays from original birthday list
begin
// MainForm.mmInfo.Lines.Add(FormatDateTime('hh:nn:ss',Now)+' Processing Request');
// First, did they send the correct secret?
if (Secret <> MainForm.edSecret.Text) then raise EXDataHttpUnauthorized.Create('Access Not Authorized');
// Second, did they request a valid day?
try
cacheindex := DayOfTheYear(EncodeDate(2000, BirthMonth, BirthDay));
except on E: Exception do
begin
raise EXDataHttpException.Create('Invalid Birthday');
end;
end;
// Alright, seems like we've got a valid request.
Result := TMemoryStream.Create;
TXDataOperationContext.Current.Response.Headers.SetValue('content-type', 'application/json');
// If the Birthday cache doesn't exist, then get the birthdays.
// We need a list of TMDb IDs that comes from that last to generate a new extended list.
if MainForm.Birthdays[cacheindex] = '[]' then
begin
Birthdays(Secret, BirthMonth, BirthDay);
end;
// MainForm.mmInfo.Lines.Add(FormatDateTime('hh:nn:ss',Now)+' Continuing Request');
// If the BirthdaysExtended cache exist, great! We don't have to do anything.
if MainForm.BirthdaysExtended[cacheindex] <> '[]' then
begin
cacheentry := Mainform.BirthdaysExtended[cacheindex];
Result.WriteBuffer(Pointer(cacheentry)^, length(cacheentry));
end
// Otherwise, we do.
else
begin
// Bunch of stuff to support SSL.
// Need to install latest OpenSSL Win64 DLL's in debug folder
// Can get the latest version from: https://indy.fulgan.com/SSL/
SSLHandler := TIdSSLIOHandlerSocketOpenSSL.Create(nil);
SSLHandler.SSLOptions.Method := sslvTLSv1_2;
// Create the HTTP Request - defaults to httpGET
// Note: httpPOST isn't going to work with this endpoint
TMDb := TidHTTP.Create(nil);
TMDb.IOHandler := SSLHandler ; //set HTTP IOHandler for SSL Connection
actors := TJSONObject.ParseJSONValue(MainForm.BirthDays[cacheindex]) as TJSONArray;
response := '[';
for j := 0 to (actors.Count - 1) do
begin
// What are we asking for?
qry := 'https://api.themoviedb.org/3/';
// qry := qry+'person/738'; // Sean Connery
// qry := qry+'person/30084'; // Anna Torv
// qry := qry+'person/524'; // Natalie Portman
qry := qry+'person/'+((actors.Items[j] as TJSONObject).getValue('TMDb') as TJSONString).Value;
qry := qry+'?api_key='+MainForm.edTMDbAPI.Text;
qry := qry+'&language=en-US';
qry := qry+'&append_to_response=image,combined_credits';
qry := TidURI.URLEncode(qry);
req := '';
try
req := TMDb.Get(qry);
except on E:Exception do
begin
end;
end;
data := TJSONObject.ParseJSONValue(req) as TJSONObject;
if (req <> '') and ((data.getValue('adult') as TJSONBool).asBoolean = False) then
begin
// MainForm.mmInfo.Lines.Add(FormatDateTime('hh:nn:ss',Now)+' Formatting Request: '+IntToStr(j+1)+' of '+IntToStr(Actors.Count));
// Name - Assume it is always present?
response := response+'{"Name":'+REST.JSON.TJSON.JSONEncode(data.getValue('name') as TJSONString)+',';
// Birthday - We got the birthday from Wikipedia, but not always set (or even the same?!) in TMDb.
// So here, we'll just use the Wikipedia version.
response := response+'"DOB":"'+((actors.Items[j] as TJSONObject).getValue('DOB') as TJSONString).Value+'",';
// if (data.getValue('birthday') is TJSONNULL)
// then response := response+'"DOB":null,'
// else response := response+'"DOB":"'+(data.getValue('birthday') as TJSONString).Value+'",';
// Deathday
if (data.getValue('deathday') is TJSONNULL)
then response := response+'"DOD":null,'
else response := response+'"DOD":"'+(data.getValue('deathday') as TJSONString).Value+'",';
// Popularity - a TMDb scoring metric
if (data.getValue('popularity') is TJSONNULL)
then response := response+'"Pop":0,'
else response := response+'"Pop":'+FloatToStr((data.getValue('popularity') as TJSONNumber).AsDouble)+',';
// Biography
if (data.getValue('biography') is TJSONNULL)
then response := response+'"BIO":null,'
else response := response+'"BIO":'+REST.JSON.TJSON.JSONEncode(data.getValue('biography') as TJSONString)+',';
// Birthplace
if (data.getValue('place_of_birth') is TJSONNULL)
then response := response+'"BP":null,'
else response := response+'"BP":'+REST.JSON.TJSON.JSONEncode(data.getValue('place_of_birth') as TJSONString)+',';
// Path to get photo
if (data.getValue('profile_path') is TJSONNULL)
then response := response+'"IMGLNK":null,'
else
begin
response := response+'"IMGLNK":"'+'https://image.tmdb.org/t/p/w185'+StringReplace((data.getValue('profile_path') as TJSONString).Value,'"','',[rfReplaceAll])+'",';
// if we wanted to include the image in the JSON, we could do it like this.
// req := TMDB.Get('https://image.tmdb.org/t/p/w185'+StringReplace((data.getValue('profile_path') as TJSONString).Value,'"','',[rfReplaceAll]));
// response := response+'"IMG":"'+TNetEncoding.URL.encodeBytesToString(bytesOf(StringReplace(TNetEncoding.Base64.Encode(req),chr(10),'',[rfReplaceAll])))+'",';
end;
// Number of roles
response := response+'"Roles":'+IntToStr(((data.getValue('combined_credits') as TJSONOBject).getValue('cast') as TJSONArray).Count)+',';
// Find top 3 most popular roles
// This is a bit of a mess as the popularity figure is completely different for TV vs. Movies.
// So we separate them out and sort them to get the top three of each, and list the movies first.
// On the client we'll decide how many of these to show, if any.
RolePopularityTV := TStringList.Create;
RolePopularityMovie := TStringList.Create;
for i := 0 to ((data.getValue('combined_credits') as TJSONObject).getValue('cast') as TJSONArray).Count - 1 do
begin
role := (((data.getValue('combined_credits') as TJSONOBject).getValue('cast') as TJSONArray).Items[i] as TJSONObject);
if (role.getValue('popularity') <> nil) then
begin
if (role.getValue('media_type') <> nil) then
begin
if ((role.getValue('media_type') as TJSONString).Value = 'tv') then RolePopularityTV.Add(RightStr('00000000'+IntToStr(Trunc(100000000-(role.getValue('popularity') as TJSONNumber).AsDouble*1000.0)),8)+'/'+IntToStr(i));
if ((role.getValue('media_type') as TJSONString).Value = 'movie') then RolePopularityMovie.Add(RightStr('00000000'+IntToStr(Trunc(100000000-(role.getValue('popularity') as TJSONNumber).AsDouble*1000.0)),8)+'/'+IntToStr(i));
end;
end;
end;
RolePopularityTV.Sort;
RolePopularityMovie.Sort;
i := 0;
if (RolePopularityMovie.count > 0) then
begin
for I := 0 to min(2, RolePopularityMovie.count-1) do
begin
role := (((data.getValue('combined_credits') as TJSONOBject).getValue('cast') as TJSONArray).Items[StrToInt(Copy(RolePopularityMovie[i],Pos('/',RolePopularityMovie[i])+1,8))] as TJSONObject);
if (role.getValue('popularity') = nil)
then response:= response+'"Pop_'+IntToStr(i)+'":null,'
else response:= response+'"Pop_'+IntToStr(i)+'":'+FloatToSTr((role.getValue('popularity') as TJSONNumber).AsDouble)+',';
if (role.getValue('media_type') = nil)
then response:= response+'"Type_'+IntToStr(i)+'":null,'
else response:= response+'"Type_'+IntToStr(i)+'":"'+(role.getValue('media_type') as TJSONString).Value+'",';
if (role.getValue('title') = nil)
then response:= response+'"Title_'+IntToStr(i)+'":null,'
else response:= response+'"Title_'+IntToStr(i)+'":'+REST.JSON.TJSON.JSONEncode(role.getValue('title') as TJSONString)+',';
if (role.getValue('release_date') = nil)
then response:= response+'"Released_'+IntToStr(i)+'":null,'
else response:= response+'"Released_'+IntToStr(i)+'":"'+(role.getValue('release_date') as TJSONString).Value+'",';
if (role.getValue('poster_path') = nil)
then response:= response+'"Poster_'+IntToStr(i)+'":null,'
else if (role.getValue('poster_path') is TJSONNULL)
then response:= response+'"Poster_'+IntToStr(i)+'":null,'
else response:= response+'"Poster_'+IntToStr(i)+'":"'+'https://image.tmdb.org/t/p/w185'+(role.getValue('poster_path') as TJSONString).Value+'",';
end;
end;
i := 0;
if (RolePopularityTV.Count > 0) then
begin
for i := 0 to min(2, RolePopularityTV.count-1) do
begin
role := (((data.getValue('combined_credits') as TJSONOBject).getValue('cast') as TJSONArray).Items[StrToInt(Copy(RolePopularityTV[i],Pos('/',RolePopularityTV[i])+1,8))] as TJSONObject);
if (role.getValue('popularity') = nil)
then response:= response+'"Pop_'+IntToStr(i+10)+'":null,'
else response:= response+'"Pop_'+IntToStr(i+10)+'":'+FloatToStr((role.getValue('popularity') as TJSONNumber).AsDouble)+',';
if (role.getValue('media_type') = nil)
then response:= response+'"Type_'+IntToStr(i+10)+'":null,'
else response:= response+'"Type_'+IntToStr(i+10)+'":"'+(role.getValue('media_type') as TJSONString).Value+'",';
if (role.getValue('name') = nil)
then response:= response+'"Title'+IntToStr(i+10)+'":null,'
else response:= response+'"Title_'+IntToStr(i+10)+'":'+REST.JSON.TJSON.JSONEncode(role.getValue('name') as TJSONString)+',';
if (role.getValue('first_air_date') = nil)
then response:= response+'"Released_'+IntToStr(i+10)+'":null,'
else response:= response+'"Released_'+IntToStr(i+10)+'":"'+(role.getValue('first_air_date') as TJSONString).Value+'",';
if (role.getValue('poster_path') = nil)
then response:= response+'"Poster_'+IntToStr(i+10)+'":null,'
else if (role.getValue('poster_path') is TJSONNULL)
then response:= response+'"Poster_'+IntToStr(i+10)+'":null,'
else response:= response+'"Poster_'+IntToStr(i+10)+'":"'+'https://image.tmdb.org/t/p/w185'+(role.getValue('poster_path') as TJSONString).Value+'",';
end;
end;
response := response + '"Work":[';
for i := 0 to ((data.getValue('combined_credits') as TJSONObject).getValue('cast') as TJSONArray).Count - 1 do
begin
role := (((data.getValue('combined_credits') as TJSONOBject).getValue('cast') as TJSONArray).Items[i] as TJSONObject);
if (role.getValue('popularity') <> nil) then
begin
if (role.getValue('media_type') <> nil) then
begin
if ((role.getValue('media_type') as TJSONString).Value = 'tv') then
begin
if (role.getValue('popularity') = nil)
then response:= response+'{"Pop":null,'
else response:= response+'{"Pop":'+FloatToStr((role.getValue('popularity') as TJSONNumber).AsDouble)+',';
if (role.getValue('media_type') = nil)
then response:= response+'"Type":null,'
else response:= response+'"Type":"'+(role.getValue('media_type') as TJSONString).Value+'",';
if (role.getValue('name') = nil)
then response:= response+'"Title":null,'
else response:= response+'"Title":'+REST.JSON.TJSON.JSONEncode(role.getValue('name') as TJSONString)+',';
if (role.getValue('first_air_date') = nil)
then response:= response+'"Released":null,'
else response:= response+'"Released":"'+(role.getValue('first_air_date') as TJSONString).Value+'",';
if (role.getValue('poster_path') = nil)
then response:= response+'"Poster":null,'
else if (role.getValue('poster_path') is TJSONNULL)
then response:= response+'"Poster":null,'
else response:= response+'"Poster":"'+'https://image.tmdb.org/t/p/w185'+(role.getValue('poster_path') as TJSONString).Value+'",';
end
else if ((role.getValue('media_type') as TJSONString).Value = 'movie') then
begin
if (role.getValue('popularity') = nil)
then response:= response+'{"Pop":null,'
else response:= response+'{"Pop":'+FloatToSTr((role.getValue('popularity') as TJSONNumber).AsDouble)+',';
if (role.getValue('media_type') = nil)
then response:= response+'"Type":null,'
else response:= response+'"Type":"'+(role.getValue('media_type') as TJSONString).Value+'",';
if (role.getValue('title') = nil)
then response:= response+'"Title":null,'
else response:= response+'"Title":'+REST.JSON.TJSON.JSONEncode(role.getValue('title') as TJSONString)+',';
if (role.getValue('release_date') = nil)
then response:= response+'"Released":null,'
else response:= response+'"Released":"'+(role.getValue('release_date') as TJSONString).Value+'",';
if (role.getValue('poster_path') = nil)
then response:= response+'"Poster":null,'
else if (role.getValue('poster_path') is TJSONNULL)
then response:= response+'"Poster":null,'
else response:= response+'"Poster":"'+'https://image.tmdb.org/t/p/w185'+(role.getValue('poster_path') as TJSONString).Value+'",';
end;
end;
if i < ((data.getValue('combined_credits') as TJSONObject).getValue('cast') as TJSONArray).Count - 1
then response := response+'"end":"end"},'
else response := response+'"end":"end"}'
end;
end;
response := response +'],';
if j < Actors.Count -1
then response := response+'"end":"end"},'
else response := response+'"end":"end"}';
RolePopularityTV.Free;
RolePopularityMovie.Free;
end;
end;
response := response+']';
response := StringReplace(response, chr(9), '', [rfReplaceAll]);
MainForm.BirthdaysExtended[cacheindex] := response;
Result.WriteBuffer(Pointer(response)^, length(response));
// MainForm.mmInfo.Lines.Add(FormatDateTime('hh:nn:ss',Now)+' Request Complete.');
end;
end;More Fields.
Back at the client, we'll need to update the Tabulator definition to include all the extra fields. While some have stayed the same, more or less, a few new field types are now present. There are seven images for each row of data - the actor's photo and the three most popular Movies and three most popular TV Shows. The Pop field is the "popularity" figure which we present here with a little extra formatting so that it looks more consistent.
Also, as Tabulator is playing the role of the conductor of the orchestra here, data-wise, we need to be sure that all the data we'll need elsewhere is also defined here, even though it is invisible.
var tabulator = new Tabulator("#divTabulator", {
layout: "fitColumns",
selectable: 1,
initialSort:[ {column:"Pop", dir:"desc"} ],
columns:[
{ title: "", field: "IMGLNK", width:60, headerSort:false, resizable: false, hozAlign:"center",formatter: "image", formatterParams:{height:50, width:33},
mutator: checkimage, mutatorParams: {imgtype: "person"}},
{ title: "Name", field: "Name", bottomCalc: "count",vertAlign:"middle" },
{ title: "Birthdate", field: "DOB", width:125, formatter: "datetime", formatterParams: {inputFormat: "iso", outputFormat:"yyyy-MMM-dd", timezone:"UTC"},vertAlign:"middle" },
{ title: "Roles", field: "Roles", width:95, hozAlign: "right",vertAlign:"middle" },
{ title: "Pop", field: "Pop",width:95,sorter:"number", hozAlign: "right",vertAlign:"middle", formatter:"money", formatterParams:{
decimal: ".",
thousand:",",
symbol:"",
symbolAfter:"",
precision: 3
}},
{field: "Title_0", visible:false },
{field: "Title_1", visible:false },
{field: "Title_2", visible:false },
{field: "Title_10", visible:false },
{field: "Title_11", visible:false },
{field: "Title_12", visible:false },
{ title: "", field: "Poster_0", width:60, headerSort:false, resizable: false, hozAlign:"center",formatter: "image", formatterParams:{height:50, width:33},
mutator: checkimage, mutatorParams: {imgtype: "movie"}, tooltip:function(e, cell, onRendered){ return cell.getRow().getCell('Title_0').getValue()}},
{ title: "", field: "Poster_1", width:60, headerSort:false, resizable: false, hozAlign:"center",formatter: "image", formatterParams:{height:50, width:33},
mutator: checkimage, mutatorParams: {imgtype: "movie"}, tooltip:function(e, cell, onRendered){ return cell.getRow().getCell('Title_1').getValue()}},
{ title: "", field: "Poster_2", width:60, headerSort:false, resizable: false, hozAlign:"center",formatter: "image", formatterParams:{height:50, width:33},
mutator: checkimage, mutatorParams: {imgtype: "movie"}, tooltip:function(e, cell, onRendered){ return cell.getRow().getCell('Title_2').getValue()}},
{ title: "", field: "Poster_10", width:60, headerSort:false, resizable: false, hozAlign:"center",formatter: "image", formatterParams:{height:50, width:33},
mutator: checkimage, mutatorParams: {imgtype: "tv"}, tooltip:function(e, cell, onRendered){ return cell.getRow().getCell('Title_10').getValue()}},
{ title: "", field: "Poster_11", width:60, headerSort:false, resizable: false, hozAlign:"center",formatter: "image", formatterParams:{height:50, width:33},
mutator: checkimage, mutatorParams: {imgtype: "tv"}, tooltip:function(e, cell, onRendered){ return cell.getRow().getCell('Title_11').getValue()}},
{ title: "", field: "Poster_12", width:60, headerSort:false, resizable: false, hozAlign:"center",formatter: "image", formatterParams:{height:50, width:33},
mutator: checkimage, mutatorParams: {imgtype: "tv"}, tooltip:function(e, cell, onRendered){ return cell.getRow().getCell('Title_12').getValue()}},
{field: "Work", visible:false },
{field: "BIO", visible:false }
]
});More Data.
Each of the image fields has something new as well, something that strikes more directly at the topic of this blog. Mutators are what Tabulator uses to modify the underlying data coming into the table. This is different than a formatter, which just takes the underlying data and presents it differently. A mutator changes the data directly, so any subsequent data access sees the modified form. Think of a formatter as something akin to a Delphi DisplayFormat function, and a Mutator as something akin to a Delphi Calculated Field. Not quite equivalent, but similar.
In our example, we're using a mutator function to deal with missing images. When data is loaded into the table, each of the images is checked. If it has a non-null value, then the image is left as-is. If it is null, however, then it is replaced with a reference to one of the placeholder types. And we've got three placeholder images - Person, Movie, and TV. They're not particularly great, I must admit, but you get the idea.
In the mutator definition, then, the type of placeholder is specified, as we know for each field (so far) which placeholder we want to appear. In the second tabulator, we don't know this, so we pass in a fourth option for the mutator to figure out which one, based on the data in that table, separately. Here's what the mutator code looks like.
var checkimage = function(value, data, type, params, component){
//value - original value of the cell
//data - the data for the row
//type - the type of mutation occurring (data|edit)
//params - the mutatorParams object from the column definition
//component - when the "type" argument is "edit", this contains the cell component for the edited cell, otherwise it is the column component for the column
if (value == null) {
if (params.imgtype == "person") return 'img/person-placeholder.jpg';
if (params.imgtype == "movie") return 'img/movie-placeholder.jpg';
if (params.imgtype == "tv") return 'img/tv-placeholder.jpg';
if (params.imgtype == "tvmovie") {
if (data.Type == 'tv') return 'img/tv-placeholder.jpg'
else return 'img/movie-placeholder.jpg';
}
}
else return value;
}The main takeaway here is that you can create mutators to fill in gaps in missing data, essentially providing more data to the table, or to bring in entirely separate logic or information at the time data is first loaded into the table. There are other places where mutators can be used as well (when editing data, for example) so there's never a reason to feel stuck with the data that you're starting with. Lots of opportunities to filter or adjust to suit.
Other examples where this might come into play include situations where incoming date/time data is in some random format, when you have lookups that need to be de-referenced, or when you need complex data split into separate fields (or combined) that just aren't in the data already. Mutators can access other fields in the same row (as we do with the 'tvmovie' situation) or can reference anything else, including complex calculations done on the table contents, or even on another table entirely. Again, nothing but options here.
More Tabulator.
Here's the definition for the second Tabulator, which shows the 'detail' records for the selected actor. Nothing new in this case. As mentioned with the mutator, we don't initially know whether a missing image is a missing Movie or a missing TV Show. But we have a Type field as part of each record here, which we can access in the mutator to sort out which placeholder to use.
var tabulator2 = new Tabulator("#divTabulator2", {
layout: "fitColumns",
selectable: 1,
initialSort:[ {column:"Pop", dir:"desc"} ],
columns:[
{ title: "", field: "Poster", width:60, headerSort:false, resizable: false, hozAlign:"center",formatter: "image", formatterParams:{height:50, width:33},
mutator: checkimage, mutatorParams: {imgtype: "tvmovie"}},
{ title: "Title", field: "Title", bottomCalc: "count",vertAlign:"middle" },
{ title: "Type", field: "Type", width:125, vertAlign:"middle" },
{ title: "Released", field: "Released", width:125, formatter: "datetime", formatterParams: {inputFormat: "iso", outputFormat:"yyyy-MMM-dd", timezone:"UTC"},vertAlign:"middle" },
{ title: "Pop", field: "Pop", width: 95, sorter: "number", hozAlign: "right",vertAlign:"middle", formatter:"money", formatterParams:{
decimal: ".",
thousand:",",
symbol:"",
symbolAfter:"",
precision: 3
}}
]
});More UI.
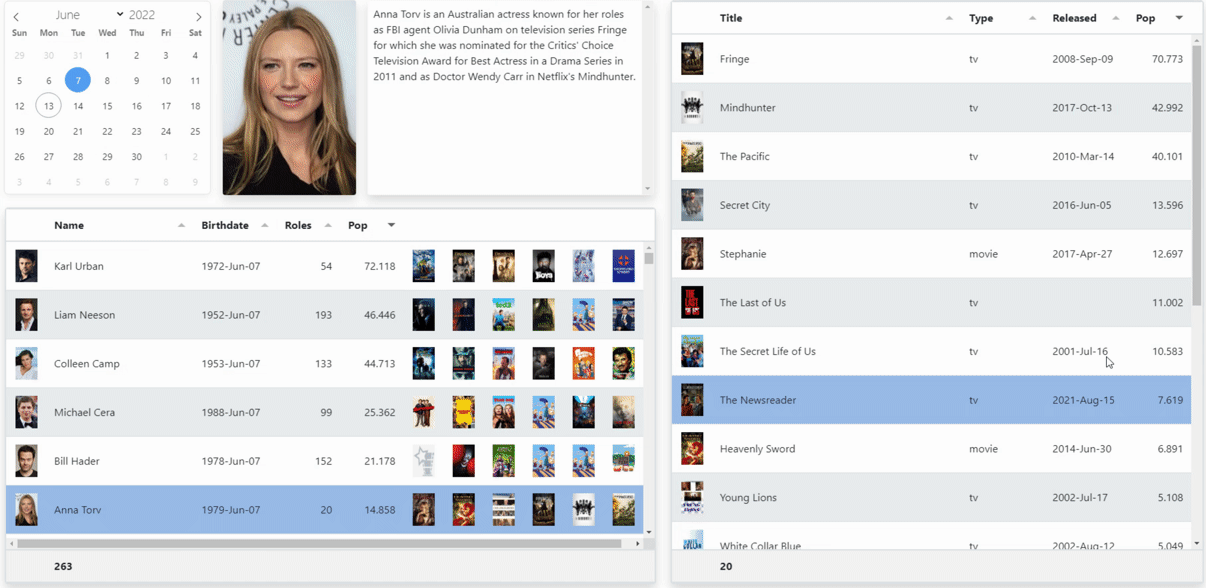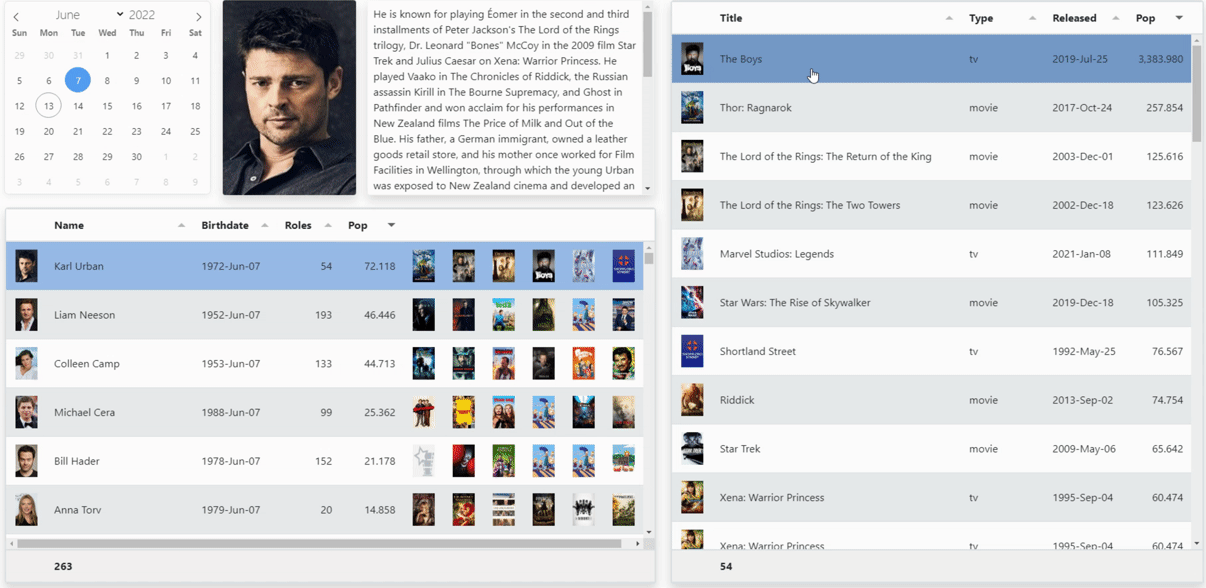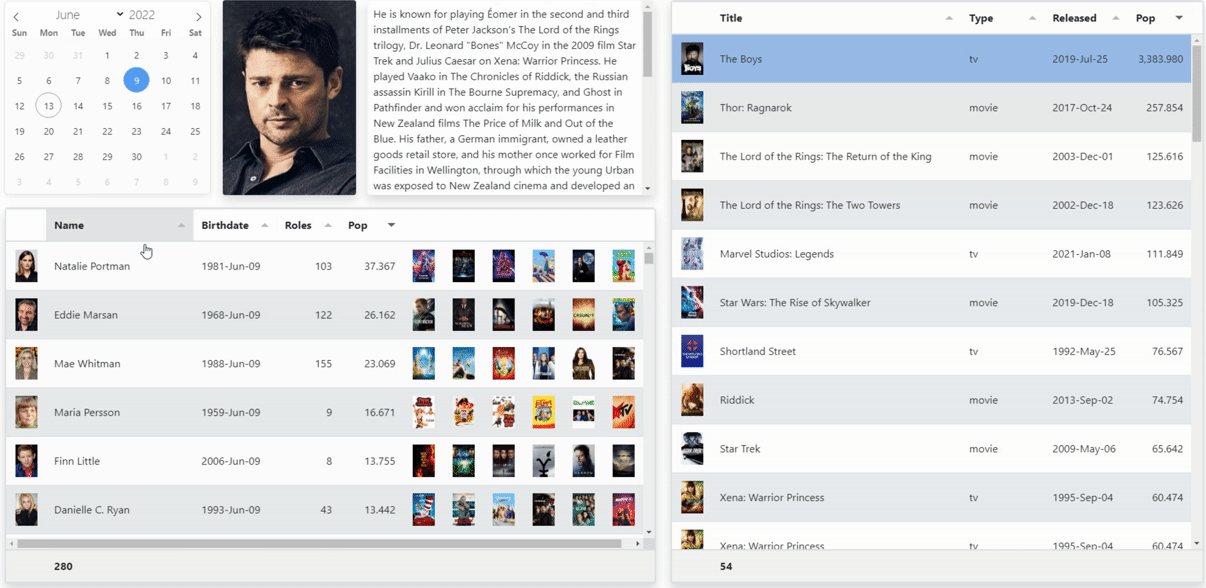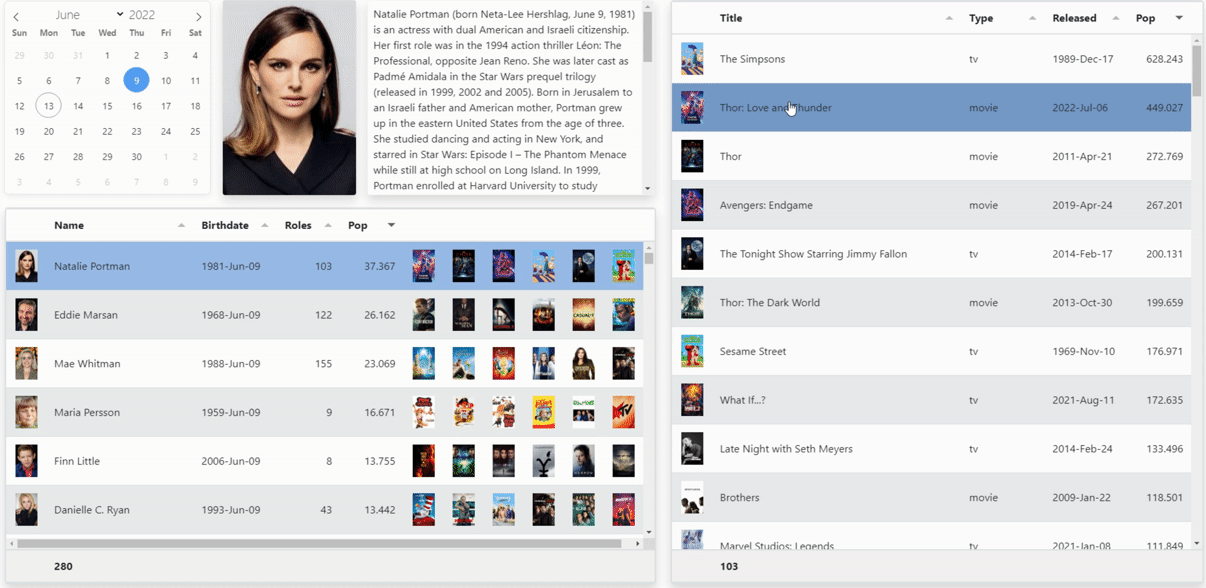
With all that data available, we can now finish up with the rest of the UI. We can drop three more TWebHTMLDivs on the Form. One for the second Tabulator table, and also a placeholder for an image and for the actor's biography. As mentioned last time out, the JavaScript grid-think is to have all the data in the grid, and then use the grid to direct other activities. So in this case, when a user selects an actor from the list that appears, it will update the photo, the biography, and the detailed list of roles they've had. We can trigger this directly from a Tabulator event by doing the following.
asm
tabulator.on("rowClick", function(e, row){
//e - the click event object
//row - row component
// Get data for subtable from Work field in main table
var data = row.getCell('Work').getValue();
var subtable = Tabulator.findTable("#divTabulator2")[0];
subtable.replaceData(data);
// Load photo from main table into DIV
var photo = document.getElementById('divPhoto');
photo.innerHTML = '<img class="rounded shadow" height=300 width=200 src='+row.getCell('IMGLNK').getValue()+'>';
// Load biography from main table into DIV
var bio = document.getElementById('divBiography');
bio.innerHTML = '<div style="width:430px; height:300px;overflow-y:scroll;" class="rounded border border-light p-2 shadow">'+row.getCell('BIO').getValue()+'</div>';
});
end;This gets us to our final objective. Now, bear in mind that the data in the clip below was all cached so everything is nice and snappy. And this is run over a local connection between the client and the XData server, so 1 MB transfers aren't even noticed. Things may look a little different otherwise.
Next Steps.
Related Posts:
Tabulator Part 2: Getting Data Into Tabulator
Tabulator Part 3: Viewing Data In Tabulator
Tabulator Part 4: Interacting With Tabulator
Tabulator Part 5: Editing Data In Tabulator
Tabulator Part 6: Getting Data Out Of Tabulator
Tabulator Part 7: Performance
Follow Andrew on 𝕏 at @WebCoreAndMore or join our 𝕏 Web Core and More Community.
Andrew Simard

This blog post has received 7 comments.
2. Thursday, June 16, 2022 at 6:04:15 PM
I think that Tabulator should be immediately inserted as a standard and visual component of TMS Webcore, even with its data binding version. It is powerful and simple and surely it could be the definitive solution for the grid that Tms Webcore currently lacks (Dbgrid is very slow, Fncgrid is cumbersome and incomplete because it is too young). Good work
Monterisi Stefano
3. Thursday, June 16, 2022 at 8:44:10 PM
While I personally think Tabulator is great, there are dozens of other JS grid components floating around that may have their own unique benefits. And we can use many of them in TMS WEB Core. Today. Trying to squeeze these kinds of controls into a DBGrid-style model, or to set them up as components in TMS WEB Core, is no easy task, and I''d really question whether it is a task worth taking up if you can use them perfectly well (and perhaps better) already without doing that work. And we''re not even halfway through the Tabulator posts, and we''re barely even scratching the surface with what can be done here, or with other similar controls. This is where I think the amazing value of TMS WEB Core comes from - being able to leverage some amazing tools, whether within TMS WEB Core, via XData, via the legacy of Delphi, or via entirely external JavaScript tools.When it comes to DBGrid and FNCGrid and FNC in general, I see the main selling feature is that you can reuse code between different platforms (VCL and Web for example). So if you''ve already been using FNCGrid in your VCL project and you''re porting to a TMS WEB Core project, then there is the potential for a big chunk of your work can be easily moved over. When I first started using TMS WEB Core, this was also where I thought my efforts would go, but I''m not directly tied to any VCL code. So having a look around, it was pretty clear that TMS WEB Core could do all that I was doing previously, and be a gateway to all this other stuff as well. Very powerful.
Simard Andrew
4. Friday, June 17, 2022 at 4:56:26 AM
Great article Andrew. I have also been looking at alternative JS grids. I have very successfully used the DevEx DevExtreme grid which has most of the features of the VCL equivalent. I will be posting examples shortly. Other DevEx components are also available for use such as the Scheduler.
Randall Ken
5. Friday, June 17, 2022 at 6:13:47 AM
Yes, working with TMS WEB Core and Tabulator, I find myself spending a lot more time thinking about WHAT to do rather than HOW to do it. Which is the point of RAD tools after all. And a much more enjoyable way to spend the day. Next time there''s a lot more of exactly this kind of thing. So fun!
Simard Andrew
6. Wednesday, January 4, 2023 at 9:48:05 PM
Another great post, Andrew! In this post your casually ;) said "There''s also no reason why we can''t create a REST server that runs under Linux, but not really the focus at the moment. Maybe we''ll convert this to a Linux XData server at a later date."Any chance you might circle back to demonstrate this? I for one am definitely interested in deploying XData to Linux
Thanks in advance.
Hazell Richard
 7. Thursday, January 5, 2023 at 12:28:14 AM
Yes, this was one of the key features of XData that initially caught my attention. I have been pretty happy running XData servers under Windows and found that I liked having other VCL components available for use within XData. But this is indeed still an interesting angle for XData. Will see where I can fit it in with the rest of the posts that are planned.
7. Thursday, January 5, 2023 at 12:28:14 AM
Yes, this was one of the key features of XData that initially caught my attention. I have been pretty happy running XData servers under Windows and found that I liked having other VCL components available for use within XData. But this is indeed still an interesting angle for XData. Will see where I can fit it in with the rest of the posts that are planned. There was also a series of posts some time ago back (2017) about this, long before I came on the scene. This might be a good place to start, I think. Part 1 of 5 is here: https://www.tmssoftware.com/site/blog.asp?post=409
Andrew Simard
All Blog Posts | Next Post | Previous Post
Monterisi Stefano