Blog
All Blog Posts | Next Post | Previous Post

 Extend TMS WEB Core with JS Libraries with Andrew:
Extend TMS WEB Core with JS Libraries with Andrew:
Tabulator Part 1: Introduction
Monday, June 13, 2022

So far, we've covered some hugely important and popular JavaScript libraries, like jQuery, Bootstrap, and FontAwesome. We've also explored other very important but somewhat lesser-known JavaScript libraries, like Luxon and CodeMirror. And some considerably smaller and less widely used JavaScript libraries like Interact.js, BigText.js, and Showdown.js. Today we're going to introduce what has quickly become my favorite JavaScript library, Tabulator, which accurately describes itself as "Easy to use, simple to code, fully featured, interactive JavaScript tables." Over the next handful of posts, we'll go into far more detail about how to make the most of it in your TMS WEB Core projects.
Why Tabulator?
Tabulator is neither wildly popular (yet!) nor particularly obscure. And it has perhaps the misfortune of falling into a hugely popular category of JavaScript libraries - defined with terms like grids or tables. If you were to do a Google search for a new JavaScript grid control, you might run through 10 or 20 before Tabulator even comes up on the list. On the other hand, if you search for a JavaScript 'data grid' on GitHub, it might come up second or third. But as with any popular JavaScript library category, there are plenty of criteria you can use to filter out which ones might be the best candidates for your projects. When I'm looking for something, these are the kinds of things I typically consider.
- Price per user or per developer, licensing terms, and so on?
- Any development activity in the past year? Does the developer respond to questions?
- Are there dependencies? Like jQuery or other JavaScript frameworks like React or Angular.
- How good/complete is the documentation? Is there plenty of example code available?
- Style vs. substance and needs vs. wants. Does it just look pretty or is it actually useful?
When the dust settles, you might well reach the same conclusion I have, and give Tabulator a try. But even if you find another control that is more suited to your needs, or perhaps you're already quite happily using another control, there's still a lot of interesting ground to cover (and some fun examples) when it comes to using any of these kinds of controls in a TMS WEB Core project.
Motivation.
The need for a grid-like control in a modern web application is usually self-evident. Displaying data for the user to see in tabular form, along with maybe some options to filter or sort that data in ways that are easy and convenient, is either something you need in your project or something you don't.
A better question for our purposes might be what the motivation is for a Delphi developer to use a new and potentially unfamiliar JS library. Particularly when it comes to providing functionality that we might already have decades of experience with, using popular, reliable, capable, and easy-to-use Delphi VCL components of various flavors.
Naturally, this need arises when moving to a different environment - the web - where our preferred set of controls may not be as readily available. At the same time, this shift to the web also brings with it opportunities to change how these kinds of applications are developed, for better and for worse.
TDataSet vs. The Web.
When we covered all those JSON examples (see Part 1 and Part 2), one of the sections (#30) showed how you could use the traditional Delphi VCL approach, combining the usual suspects, TDataSet, TDataSource, and TDBGrid. In TMS WEB Core, their equivalents might very well be TXDataWebDataSet, TWebDataSource, and TWebGrid. Great! So we can just use those and carry on as we have been, right? Well, not necessarily. Some parts of the 'infrastructure' we've been relying on for so long have changed, and potentially so has the overall environment our apps run in, regardless of development tools. So while you can mimic that development pattern, you might not want to.
Traditionally, for example, a Delphi VCL application might run on a corporate-managed Windows desktop, connecting to a corporate database, directly via a fixed corporate local area network. The key word here is 'corporate' and implies that the entire environment is under strict, professionally managed controls. And while security and application availability (a catchall phrase for database uptime, network uptime, and application uptime) might very well be at the top of your IT department's list of priorities, the organization controls all the pieces.
You've got a good chance at making this work really well with relatively few surprises at this stage. And while moving to a web platform doesn't require forgoing any of these things, generally one of the benefits of a web platform is that you can. Devices running your application may now be entirely outside of your control. The public internet (including potentially wireless carrier networks) may carry some or all of the network traffic. And the users of your application may not necessarily be employees of your organization, or even aligned with the interests of your organization.
Efforts around security and application availability might now be orders of magnitude more complex. Yet all of this is potentially fantastic for all stakeholders - which is why it is being done everywhere at such a large scale.
The Stateless World We Live In.
Perhaps the biggest driver pushing us away from the traditional TDataset model is the stateless nature of the world today, at least in terms of APIs. When you have a persistent connection to a database, the database is in essence maintaining a connection (perhaps with the help of a connection pool) internally for a particular user's exclusive use. And this works fantastically well when you have dozens, hundreds, or maybe even thousands of known users connecting to a database. Beyond that, maintaining these connections, or this 'state' becomes a real problem - a limiting bottleneck, even.
Web servers long ago, and REST servers more recently, figured out that by becoming stateless, this bottleneck could be eliminated and the server side of the equation could be simplified. Now, each time a connecting client application makes a request, a relatively generic server endpoint process can be spawned dynamically to process the request and then just as quickly dispose of itself and return whatever resources it was using back to the server. Each such spawned process starts from a blank (stateless) page and relies on the client providing enough context to correctly and efficiently and securely respond to its request.
This is essentially what something like an XData server might provide to a TMS WEB Core application. Servicing requests for three users per day vs. three million users per day, from an application development standpoint, takes no additional effort. Sure, you might have to run more copies of the XData server, potentially running on more server instances, with all kinds of networking infrastructure, but the application coding is the same. Technologies like SSL and JWT can abstract away a lot of the new complexity from the developer.
Exploring this stateless concept a bit further, the client application can cache whatever state is needed, and even whatever responses have already been processed, and thus manage the entire user experience, sometimes without any subsequent server connection whatsoever. It reaches out to a server only to get the bare minimum data needed to provide the functionality required, and only if it doesn't already have the data. Essentially, server traffic is minimized while the bulk of anything data-related is handled entirely client-side once data has been successfully retrieved.
Examples of how this plays out in real-world applications can be found everywhere. In an online banking web app, let's say you log in and then see a list of recent transactions made against your account. While still logged in, let's say you process an online purchase transaction on another website in another tab in your browser. Typically, in my experience, that new online transaction will not show up in the list of transactions in your online banking web app, even if you refresh the page. It is not until you explicitly log out and then log in again that the transaction will appear. This is because the client application (your online banking web app) retrieves a list of transactions when you first logged in and doesn't normally refresh that data, even on a page reload - it just caches the data locally and refers to that exclusively.
If you perform a transaction during your session in the online banking web app itself, that transaction will be shown immediately. The web app presumably reloads the data in that instance, updating its client data at the same time that the transaction is negotiated at the server. This approach introduces a very minor inconvenience to the web app user, in terms of not always having the most accurate data presented to the user during their session. But that scenario likely comes up in a tiny fraction of all user sessions in any given period. On the other hand, this little optimization likely reduces the overall network requests made by the web app to the banking systems' servers by an order of magnitude.
A side effect of this kind of overall model, bringing it back to our grid controls, is that the grid controls, as a group, have grown in complexity and scope to incorporate more of the overall client management of the data, once it has been retrieved from the server. Instead of having a bunch of different components working together to pass information back and forth to produce a particular user experience, you end up with a grid control that manages all of the data and just tells you when something has changed.
Such controls may then end up having the appearance of being more monolithic in nature. But they may also be supported with an entire ecosystem of their very own, consisting of plugins, add-ons, and overrides to accommodate all the different kinds of user experiences that developers are after. Instead of having a TDataSet and a TDataSource hold the data, and other controls to manipulate or display the data, you have just one grid control that does everything for you once you give it the data.
This is largely how Tabulator in particular, and often other JavaScript grid controls in general, see the world. Typically, there is very little support in terms of communicating with a server, if any. And things we might be familiar with, like lookup fields and calculated values that we normally think of as having nothing to do with a grid other than for display purposes, gives way to a scenario where the grid itself manages all of these kinds of things as much as possible internally.
And, as a developer, interactions with the grid are in some respects restricted to providing the data going into the grid and processing the data (edits or other changes) coming out of the grid. The grid handles everything in between via an array of options or configuration settings. This is why a good grid can be a tremendously powerful tool in the client application toolbox. And also why it can be enormously difficult at times to coerce a grid to do anything it wasn't originally designed to do, particularly if it isn't well-supported or well-engineered to begin with.
Now, having said all that, there are so many options available to a developer today, using TMS WEB Core or otherwise, it is not inconceivable that a determined developer could make any kind of client/server arrangement work in terms of connections, persistence, caching, pooling, drivers, JavaScript libraries, ORM's, app virtualization tools, and so on. I've no doubt that someone could create an app that mirrors its VCL equivalent very, very closely.
Even beyond that, there are at least a handful of third-party tools for publishing a Windows-based Delphi VCL app on a web page directly, if you were so inclined. All to say that, as a developer, and particularly as a TMS WEB Core developer, you've got options! And likewise, with the various grid controls, most can be extended or adjusted or otherwise coerced into behaving a certain way, but as developers, we don't really want to have to reinvent everything all the time. Things like column headers with sort buttons should be available with sensible defaults and overrides available when the defaults aren't what you're after. Simple UI designs should be quick and easy. Complex UI designs should be, at the very least, possible.
Tabulator First Steps.
As we've been doing all along, the first step in adding Tabulator to your project is to include it in your Project.html file, either by adding it manually or via the Manage JavaScript Libraries feature of the Delphi IDE. The usual JavaScript and CSS file applies here, and we'll also include Luxon here as well, as Tabulator uses this to handle all of its date and time formatting functionality.
<!-- Tabulator -->
<script src="https://cdn.jsdelivr.net/npm/tabulator-tables@5/dist/js/tabulator.min.js"></script>
<link href="https://cdn.jsdelivr.net/npm/tabulator-tables@5/dist/css/tabulator.min.css" rel="stylesheet"/>
<script src="https://cdn.jsdelivr.net/npm/luxon@latest/build/global/luxon.min.js"></script>As of this writing, Tabulator is at v5.2.7. Updates come out regularly, with minor updates usually at least every few weeks and bigger updates every month or two. When major updates come out, there's a good chance there will be breaking changes, as happened in the upgrade from v4 to v5 of Tabulator. So best to keep that @5 in place in the CDN link instead of @latest in this case.
Even though the developer might post comprehensive upgrade instructions, it naturally takes time and effort to update and test your code when this kind of situation comes up. The usual warning about whether to use a CDN or a local copy of the library, therefore, applies here as much as it has in any of the libraries we've covered. Perhaps more so. The developer is also proactive about adding warnings to the console when features that you might still be using have been deprecated.
Note that I'm not as worried about this kind of thing with Luxon however, as even if that project were to introduce breaking changes, which is highly unlikely in itself, the scope of Luxon in my projects is not likely to cause the same kinds of problems as Tabulator breaking. But your situation may be different, so adjust accordingly.
By default, Tabulator will happily try and display whatever JSON data you throw at it. When initializing a Tabulator element, you can also pass it JSON directly. The element is attached to an HTML element in your form, just as we've seen previously with FlatPickr or any of the other JavaScript controls.
To get up and running with a minimum amount of effort, drop a TWebHTMLDiv component on the form, and set its Name and ElementID property to 'divTabulator'. If you want the table to be the same size as the data it contains, then set the heightStyle and widthStyle properties to ssAuto. Finally, add a bit of JavaScript code to the WebFormCreate procedure along with a sample JSON array with the data to display in the table. The result should be something like the following.
procedure TForm1.WebFormCreate(Sender: TObject);
begin
asm
var sampledata = [
{ID: 1, First: "Andy", Last: "Zikman", Birthday: "2001-01-01", Description: "Never been contacted." },
{ID: 2, First: "Bruce", Last: "Yates", Birthday: "2002-02-02", Description: "Actively supports our cause." },
{ID: 3, First: "Charlie", Last: "Xander", Birthday: "2003-03-03", Description: "'Get off my lawn!'" },
];
var tabulator = new Tabulator("#divTabulator", {
data: sampledata,
autoColumns: true,
layout: "fitDataTable"
});
end;
end;When you run the app, you should end up with a fully functional, albeit simple, Tabulator table. Columns and their headers are created automatically from the names of the JSON array's object elements, with the column widths set wide enough to hold their contents. Sorting up/down works as expected, handled automatically. When it comes to the overall display of the table, the "fitDataTable" layout mode adjusts the width and height of the table to fit all the data that it contains. Usually, I tend to use a different layout, fitting the data to a fixed-sized table, but this works fine for now.
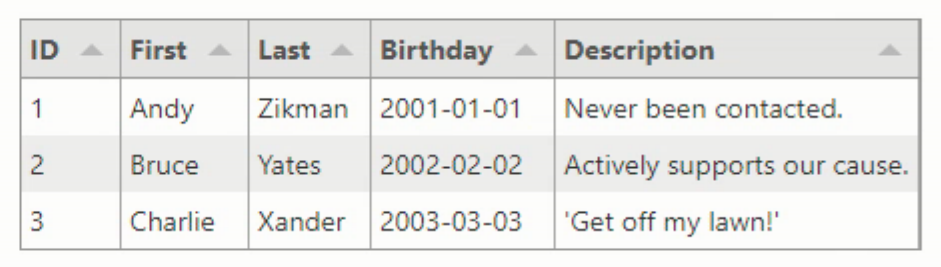
That's all there is to it, as far as getting started. There are many more options that can be passed, and normally the columns will be explicitly defined - we'll get to that in just a moment. The sample data is passed to Tabulator as a simple JSON array, so the usual JSON datatypes are available. This is rather limiting but we'll be addressing that more directly in the second Tabulator blog post, "Getting Data Into Tabulator". For now, we'll just assume that the dates are being displayed in the format that we want.
Column Definitions.
In our example above, the names of the columns, their widths, default sorting options, and so on were automatically configured without having to do anything. If this works for your particular set of data, great! However, if you want to exert more control over things, often the first place to start is to define the columns yourself.
For example, if your JSON data is coming from elsewhere, perhaps you want to change the column names to something more specific to your application. Or perhaps there's no need to sort certain columns. Or maybe some columns that are in the data do not need to be displayed or maybe could be displayed differently. Column definitions have quite a large number of configurable options, which we'll really get into in the third blog post, "Viewing Data In Tabulator". We'll do a few things right away though, to help get a feel for how this all works.
var tabulator = new Tabulator("#divTabulator", {
data: sampledata,
layout: "fitDataTable",
columns:[
{ title: "ID", field: "ID", visible: false },
{ title: "First Name", field: "First", bottomCalc: "count" },
{ title: "Last Name", field: "Last" },
{ title: "Birthday", field: "Birthday", headerSort: false, formatter: "datetime", formatterParams: { inputFormat: "yyyy-MM-dd", outputFormat:"MMM dd" }},
{ title: "Donor Description", field: "Description" }
]
});Each column has a number of properties that can be set. Here's where we're at so far.
- title is the text appearing in the column header.
- field is the name of the JSON object in the array.
- visible determines whether the column is visible. It can still be accessed via JavaScript.
- headerSort controls whether the sort arrow is available.
- formatter is used to specify what kind of format the data will contain.
- formatterParams is used to supply extra information to the formatter when needed.
- bottomCalc adds an extra row at the bottom with summary functions, like the record count in this case.
In this example, our formatter is actually a function that calls Luxon internally to convert a date from one custom format to another. There are more than a dozen built-in formatters to help with the most common kinds of data, including images, currency, custom HTML, dates/times, progress bars, stars, checkboxes, and so on. It is also possible to define an entirely custom formatter to do whatever you like. Our updated Tabulator table now looks like this.
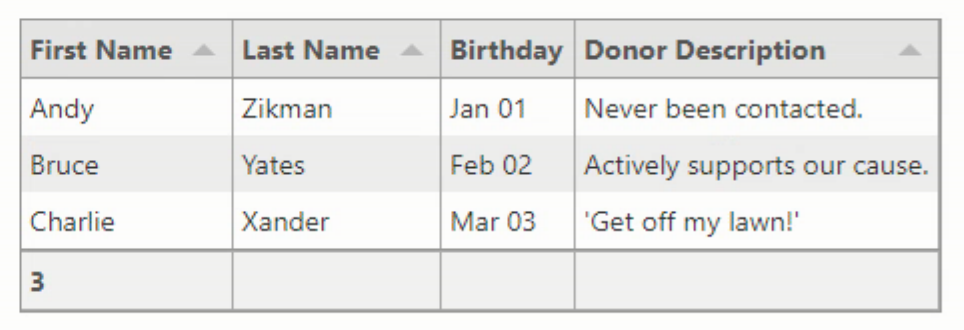
Table Definitions.
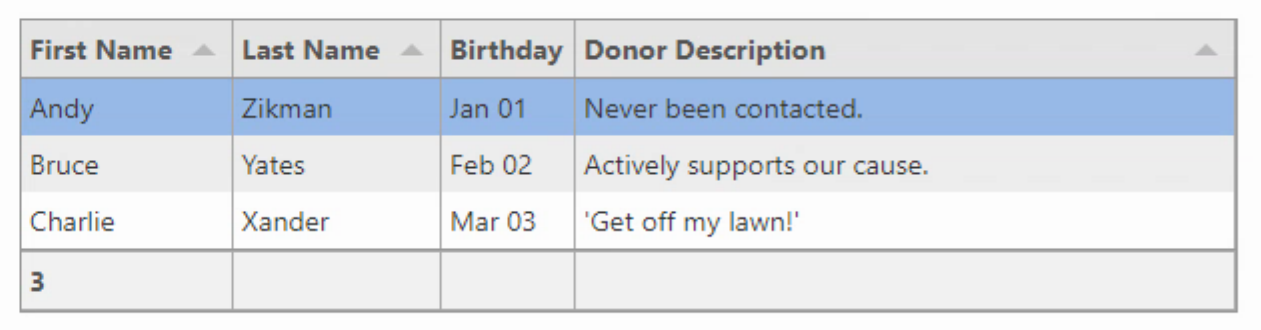
Most of the time spent customizing Tabulator will likely be spent customizing those kinds of column definitions. Adding in extra calculations or sizing information or any of a hundred different things. But there are also quite a lot of options that impact the appearance and function of the table as a whole. We already have an example of one layout type, but there are also options related to reordering columns and rows, copy & paste features, resizing elements, frozen columns, and many, many more. So let's try a few here.
We'll change the layout so that the columns fill a fixed-width table, with the last column stretching if necessary. We'll allow all of the columns to be reordered, simply by dragging the column headers left and right. The rows can be reordered as well, by dragging them up or down. And we'll allow all the columns to be resized except for the date. And finally, we'll set an option to have at most one of the rows be selectable.
var tabulator = new Tabulator("#divTabulator", {
data: sampledata,
layout: "fitDataStretch",
movableRows: true,
movableColumns: true,
resizableColumnFit: true,
selectable: 1,
columns:[
{ title: "ID", field: "ID", visible: false },
{ title: "First Name", field: "First", bottomCalc: "count" },
{ title: "Last Name", field: "Last" },
{ title: "Birthday", field: "Birthday", headerSort: false, resizable: false, formatter: "datetime", formatterParams: { inputFormat: "yyyy-MM-dd", outputFormat:"MMM dd" }},
{ title: "Donor Description", field: "Description" }
]
});The result is a table that might be starting to look a lot more like the Delphi VCL-style tables many of us have worked with for such a long time.
Tabulator Defaults.
If you are planning on having many Tabulator tables in your project (I have several dozen spread throughout many different forms in one particular project) then it can be sometimes convenient to set Tabulator defaults for many of the most common options. This leaves your actual Tabulator definitions with only simpler column definitions and maybe a few exceptions here or there, cleaning up things dramatically. The only catch is that the Tabulator defaults have to be defined before any Tabulator tables are created.
If your project has a DataModule as the first unit that is created, then setting these defaults in the create procedure for that module would be ideal. But for now, we just have to make sure it comes first in our example here. Tabulator defaults can also include column defaults, which will become even more helpful when we dig further into all the column options that we can define. Here's an example of how I've set the Tabulator defaults in some of my projects.
asm
Tabulator.defaultOptions.index = "ID";
Tabulator.defaultOptions.height = "100%";
Tabulator.defaultOptions.layout = "fitColumns";
Tabulator.defaultOptions.resizableColumnFit = true;
Tabulator.defaultOptions.layoutColumnsOnNewData = true;
Tabulator.defaultOptions.selectable = 1;
Tabulator.defaultOptions.scrollToRowPosition = "center";
Tabulator.defaultOptions.columnHeaderSortMulti = true,
Tabulator.defaultOptions.clipboard = "copy";
Tabulator.defaultOptions.columnDefaults = {
resizable: false,
headerHozAlign: "left",
hozAlign: "left"
};
end;About the Documentation.
The Tabulator documentation is some of the best you're likely to come across. Quite easy to find more information about any and all options. And there are code examples throughout along with working demos to showcase many of the options that are available. The developer is incredibly responsive to questions (which should be posted on StackOverflow) and bug reports (which should be posted on GitHub), and there's even a Discord server where a community of people (which periodically includes me) are available to help.
They are a bit particular when it comes to posting bug reports though, so if you think you've found something that is broken and want to report it, be mindful that you'll need to fill out a proper bug report including a JSFiddle or equivalent to help them figure out what is wrong. And of course, they only know about JavaScript and won't be all that keen to help with TMS WEB Core-specific questions. Please post those to the TMS Support Center, even if they're related to Tabulator.
One tiny caveat about the documentation, though. If you happen to use Google to search for Tabulator options (Google 'tabulator layouts' for example), it will likely drop you directly onto the page you need, but more than likely it will drop you into the documentation for an older version of Tabulator. There will be a message at the top of the page reminding you of this, but still, something to be mindful of. Switching the version to the one you're using is easy enough - there's a dropdown setting right there, and you'll usually be redirected right to the same page in the newer documentation.
Next Steps.
That's everything I wanted to cover in this (quick?!) introduction. But I've got a bunch more posts planned!
- Getting Data Into Tabulator: We'll get data from a few different data sources, and explore options about how to massage the data on its way in. Potentially interesting even if you're not planning on using Tabulator at all.
- Viewing Data In Tabulator: All the things I can think of here, including all the formats, grouping, filtering, sorting, theming, popups, lookups, pagination, navigators, and so on.
- Editing Data In Tabulator: Lots of material to cover here, particularly about what to do when Tabulator data is changed, but also about how it can be changed, undoing changes, writing changes to a database, more advanced uses of the Tabulator events system, and adding data to a Tabulator table that already has data in it.
- Getting Data Out Of Tabulator: Topics here will include exporting PDF, CSV, JSON, HTML, and XLS files, customizing the built-in copy and paste functionality, and handling download and print functionality in different client environments, as well as a bit about notifications.
- Special Tabulator Topics: The last Tabulator post will be about whatever is left. And maybe, just maybe, a fun little app to help showcase some of what we've covered.
Taublator Part 1: Introduction
Tabulator Part 2: Getting Data Into Tabulator
Tabulator Part 3: Viewing Data In Tabulator
Tabulator Part 4: Interacting With Tabulator
Tabulator Part 5: Editing Data In Tabulator
Tabulator Part 6: Getting Data Out Of Tabulator
Tabulator Part 7: Performance
Follow Andrew on 𝕏 at @WebCoreAndMore or join our 𝕏 Web Core and More Community.
Andrew Simard

This blog post has received 7 comments.
2. Wednesday, June 15, 2022 at 10:43:24 AM
Then you are in luck! I have FIVE more posts planned, in quick succession. What kinds of things do you want to read about with respect to Tabulator?
Simard Andrew
3. Wednesday, June 15, 2022 at 1:26:22 PM
Source code for the samples would be great!
Maierhofer Bernd
4. Wednesday, June 15, 2022 at 2:38:14 PM
Yes, source code for everything is included.
Simard Andrew
5. Thursday, June 16, 2022 at 10:17:04 PM
Thank you very much for these detailed blog posts. "Getting Data Into Tabulator" is out, and I hope there is not so much time that you post the next parts "Viewing Data" and "Editing Data". Please postpone your summer vacation until we see these parts here at TMS blogs ;-)
Gentes Peter
6. Thursday, June 16, 2022 at 10:26:10 PM
No problem at all ;-)
Simard Andrew
7. Friday, June 17, 2022 at 5:44:32 AM
Andrew,As you mentioned above, I also tried some google searched frameworks while looking for an alternative javascript grid to TDBGrid. However, when I saw your first posts about Tabulator in your TMS Web Core group, I started to evaluate this framework. And I can say it''s the best grid I''ve ever used. Since then, I have been following your posts closely.
Borbor Mehmet Emin
All Blog Posts | Next Post | Previous Post
Ebikekeme Ere