Blog
All Blog Posts | Next Post | Previous Post

 Delphi is 27, happy birthday and welcome to the new generation
Delphi is 27, happy birthday and welcome to the new generation
Monday, February 14, 2022
Happy Birthday Delphi
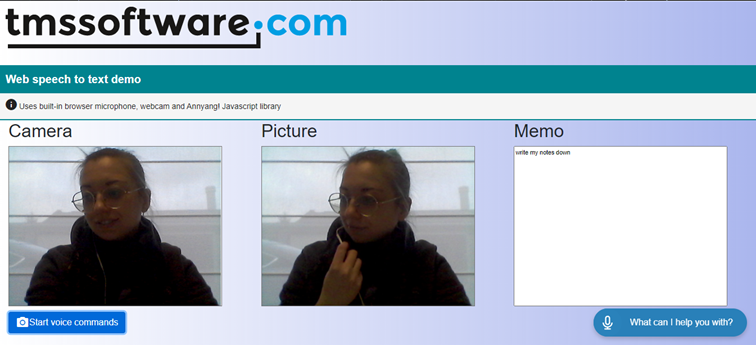
It is meanwhile a regular. It is again February 14 and it is the birthday of Delphi. We celebrate today 27 years! Not including its predecessor Turbo Pascal, it's for a whole generation of software developers already well over the half of a career that Delphi gives us professional satisfaction as well as bread on the table. But today, I wanted to devote this birthday of Delphi to the next generation. The new generation that is at the start of a new software development career. The new generation that discovers Delphi and is feeling enthusiasm and the new generation for which Delphi still is a valuable & productive tool to accomplish real-life software development tasks that has an impact on people's lives. Enough said, read the article Stephanie Bracke, our intern this year at TMS software wrote herself or watch the video she made herself! See or read & be amazed about what Stephanie accomplished for Delphi apps that can change people's lives, including people with disabilities.
Bruno
Stephanie.Introduce('Hello world');

When I first started my internship at TMS software, I felt overwhelmed and that still feels like an understatement, but luckily my mentor Bruno repeatedly told me ( and I needed to hear that every time as well ) that in order to be able to run, you should learn how to walk. To get started and prepare myself during the summer holidays, I was given a two book, the first by Marco Cantù and another by Holger Flick. to try to get myself familiar with the Delphi IDE and also the Object Pascal language.
My project
For my first real assignment I was given an open source library called Annyang! And was the task was to study this library and turn this into an easy to use speech to text component for TMS WEB Core.
I feel like creating the TSpeechToText component with Annyang! Is like entering a rabbit hole, in school we learned the basics, but the deeper you go, the more there is to learn!
In short, I created a web application with TMS WEB Core and only one button that starts Annyang. But of course, you can start the engine automatically at application startup or in different ways, if you don’t like that button. You’re as free as a bird here!
Once the button on my webpage is clicked, the device microphone gets activated (see red little icon the caption) in your browser and Annyang starts to listen to your command.
I added a few commands, for example:
- Start -> starts the camera
- Snap ->takes a picture
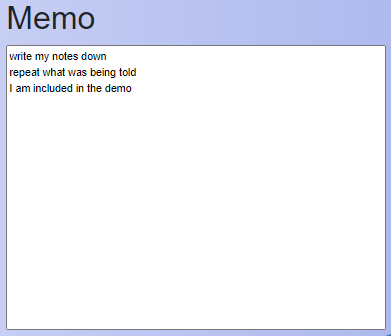
- Listen -> Annyang starts listening to sentences and adds it to the memo
Once you activate the “Listen” command, Annyang will still listen to single word commands and execute those as a priority instead of adding the recognized words in a TWebMemo control, whenever that single word is used in a sentence, the entire sentence will be written down without execution of said command.
There are also commands like zoom, reset, pause and resume but those are for you to find out in the demo!
A deeper look into my code
procedure TSpeechToText.Start;
begin
if UseAsDictaphone = true then
Dictate()
else
Command();
// direct JavaScript interface to the Annyang library
asm
if (annyang){
annyang.start();
SpeechKITT.annyang();
SpeechKITT.setStylesheet('css/skittUi.CSS');
SpeechKITT.vroom();
}
end;
end;But.. what’s the difference between the command and the dictate function?
procedure TSpeechToText.Dictate;
procedure HandleDictaphone(ADictate: string);
begin
if Assigned(OnDictate) then
OnDictate(Self, ADictate);
end;
begin
asm
if (annyang){
var commands = {
'*variable': repeatUser
};
function repeatUser(userSentence){
HandleDictaphone(userSentence);
}
annyang.addCommands(commands);
}
end;
end;Annyang understands commands with named variables, called splats in Annyang convention, ( which have been used here for the dictate function ) and optional words.
When the dictate function gets called, Annyang will not only be listening to every word separately, but will convert the spoken words and sentences to text that can be added to a memo control. And this dictate part is also included in the demo:
The alternative way is to let Annyang listend to commands and in the TSpeechToText component, trigger an event handler when Annyang heard the command word:
procedure TSpeechToText.Command;
var
i: Integer;
cmd: string;
procedure HandleCommand(ACommand: string);
var
vc: TVoiceCommand;
begin
vc := FVoiceCommands.Find(ACommand);
if Assigned(vc) and Assigned(OnCommand) then
OnCommand(Self, vc);
if Assigned(vc) and Assigned(vc.OnCommand) then
vc.OnCommand(vc);
end;
begin
for i := 0 to FVoiceCommands.Count -1 do
begin
cmd := FVoiceCommands[i].Command;
asm
if (annyang){
var Function = function() {}
var commands = {};
commands[cmd] = Function;
annyang.addCommands(commands);
}
end;
end;
asm
if (annyang){
annyang.addCallback('resultMatch', function(phrase,cmd,alt)
{
HandleCommand(phrase);
} );
annyang.addCallback('resultNoMatch', function(phrases)
{
HandleNoMatch(phrases);
} );
}
end;
end;First the commands, stored in a collection, get added to the engine and as you can see when a command gets recognized by Annyang, it will trigger the event handler from where whatever action you want it to do can be called.
Which command is linked to what action is entirely up to you, thanks to this easy to use collection with collection item event handlers!
Command’s can be added in 2 ways, by using the designer in your Delphi IDE like this:
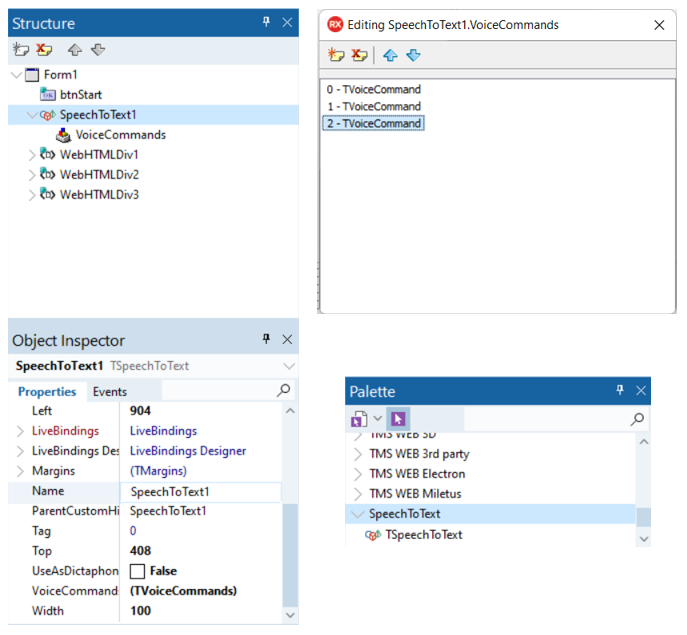
or by writing the code for it manually like this:
var vc: TVoiceCommand; begin vc := SpeechToText.VoiceCommands.Add; vc.Command := 'Start'; vc.OnCommand := MyVoiceCommandStartHandler; end;
Once the command was added to the VoiceCommands collection as a TCollectionItem, working with voice commands event handler is just as simple as:
procedure TForm1.MyVoiceCommandStartHandle(Sender: TObject); begin WebCamera1.Start; end;
My component is coming!
Right now, I'm polishing and refactoring the component a little bit and create a distribution with package and when this is ready, the TSpeechToText component will be added as a free and open source component to the page of extra components for TMS WEB Core. I'm curious what you envision using TSpeechToText for in your apps, so let me know in the comments.
Stephanie
Bruno Fierens

This blog post has received 8 comments.
 2. Tuesday, February 15, 2022 at 8:36:12 AM
The FNC WX pack has such a component. It doesn''t return the audio as files but plays them directly on your device.
2. Tuesday, February 15, 2022 at 8:36:12 AM
The FNC WX pack has such a component. It doesn''t return the audio as files but plays them directly on your device.
Bradley Velghe
3. Tuesday, February 15, 2022 at 10:53:42 AM
I was just making a suggestion, and that component doesn''t solve the proposed problem anyway.Schwartz David
4. Tuesday, February 15, 2022 at 11:57:36 AM
Creation of the SpeechToText component took me 12 working days from scratch, that includes doing the “Annyang!” research and testing before actually getting started with the component itself.
Please keep in mind that I didn''t have any previous experience at all.
So far the plans were to polish and finish the SpeechToText component, because during development I learned what to prioritise and to understand what a developer actually needs, based on this newfound knowledge it is great for me to implement these things in order to finish it as a complete component.
If I remember correctly there already is a TextToSpeech type of component, namely SpeechSynthesis, but considering for speech input that the SpeechToText component takes spoken commands or sentences in as a string datatype, there should be plenty of possibilities for similar implementation when combining both (non-visual)components.
Though this wouldn''t give you back audio files like the mp3 of wav you gave as an example, it could still work back and forth between the SpeechToText and SpeechSynthesis components as string datatypes.
(Stephanie)
Masiha Zemarai
5. Thursday, February 17, 2022 at 6:03:41 PM
Nice pice of work!!
G Lund
6. Saturday, February 19, 2022 at 1:47:16 AM
12 days? Is that ALL? That''s pretty amazing if you had no previous Delphi experience! Just goes to show how productive and easy-to-learn and use Delphi is.
Schwartz David
7. Wednesday, December 7, 2022 at 10:46:57 PM
Curious, have been wanting to add Speech to Text to my application. Tried Microsoft in the OS and it worked great with no code on my part, just highlight the field and enable the feature. The application is for remote control of a serial connected device to my PC. However, when not in WiFi or Cellular coverage the Microsoft Windows component failed. Obviously, it required a Web based server to do the conversion. This being a WebCore component obviously has the same dependency.Are there plans to make a standalone component for SpeechToText? It would be the perfect enhancement to any mobile application for a true "hands free" experience.
Steven Ollmann
8. Thursday, December 8, 2022 at 4:02:26 PM
We use the official browser API for this. If this is a Google based browser engine, this browser speech to text API indeed requires an internet connection.
Sadly, this is a browser API limitation so far. Maybe Google will change this in the future.
Bruno Fierens
All Blog Posts | Next Post | Previous Post
Do you have plans to now make a TextToSpeech component? I''m curious because I was using a phone service today to request something and it accepted both pressing on the phone buttons and speech input. It then repeated back to me what it thought my response was, and it was all dynamically generated speech. I entered my phone# on the keypad and it read back the numbers for me to verify. It then asked for my address, and I spoke it, then it repeated it back to me perfectly.
This would be another non-visual component that would have to send text to a service and then get back audio files (eg, mp3 or wav) and play them in sequence, possibly with some pauses added in between.
Schwartz David